本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
SageMaker JumpStart
SageMaker JumpStart 为各种问题类型提供预训练的开源模型,以帮助您开始使用机器学习。您可以在部署之前逐步训练和调整这些模型。 JumpStart 还提供了为常见使用案例设置基础架构的解决方案模板,以及使用 SageMaker 进行机器学习的可执行示例笔记本
您可以通过亚马逊的 JumpStart 登录页面访问预训练的模型、解决方案模板和示例 SageMaker Studio。以下步骤显示如何访问 JumpStart 使用亚马逊的模型和解决 SageMaker Studio。
您也可以使用 SageMaker Python 开发工具包。有关如何使用的信息 JumpStart 通过 API 以编程方式进行模型,请参阅使用 SageMaker 预训练模型的 JumpStart 算法
打开 JumpStart
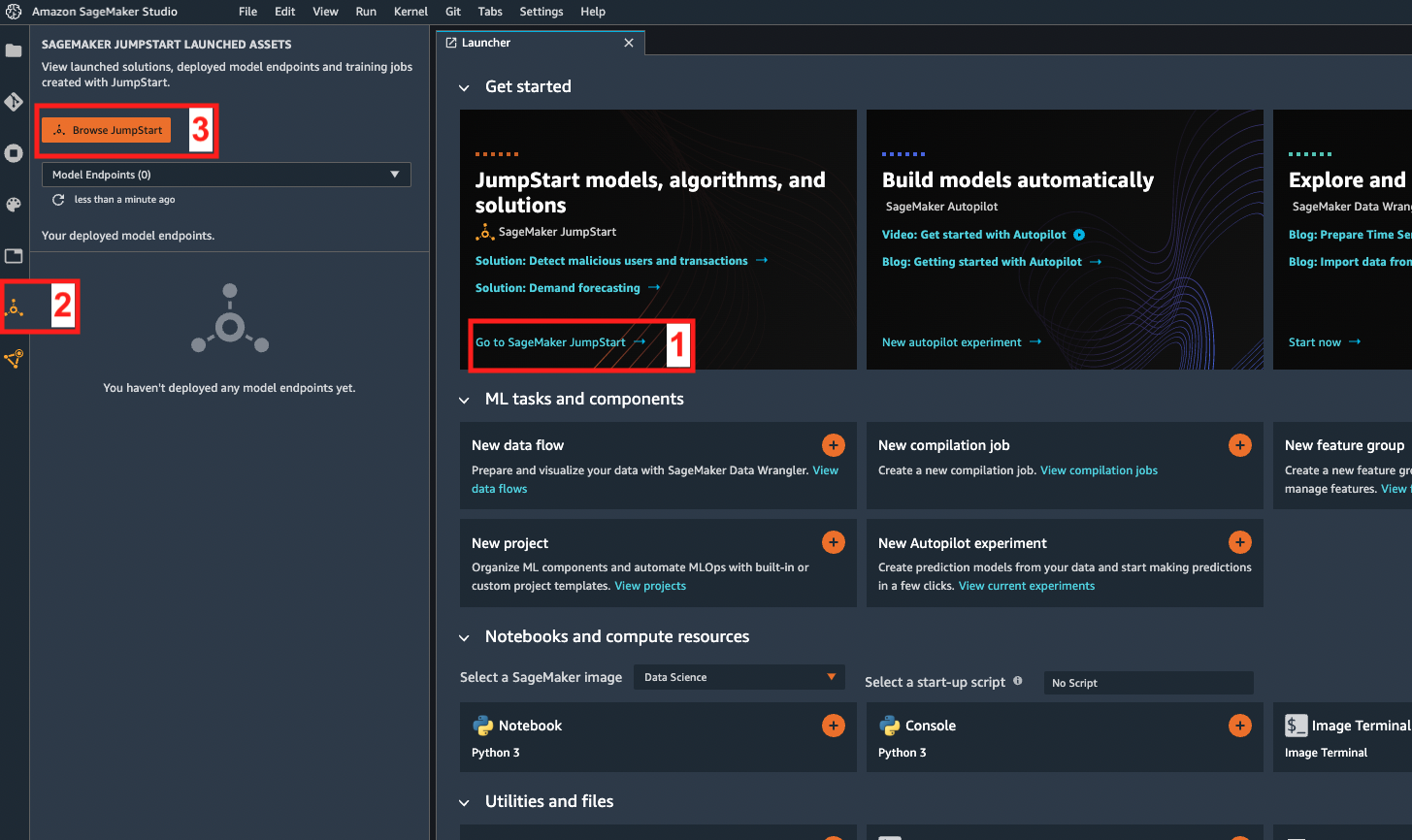
在 Amazon 中 SageMaker 工作室,开放 JumpStart 使用以下操作之一:
-
这些区域有: JumpStart 中的启动程序开始使用部分。
-
这些区域有: JumpStart (图标
 ) 在左侧边栏.
) 在左侧边栏. -
这些区域有:浏览 JumpStart按钮在已启动的资源窗格中。
在下载或使用第三方内容之前:您有责任查看并遵守任何适用的许可证条款,并确保它们在您的使用案例中可以接受。
使用 JumpStart
从 SageMaker JumpStart 登录页面,您可以浏览解决方案、型号、笔记本电脑和其他资源。您还可以查看当前启动的解决方案、终端节点和培训作业。使用 JumpStart 搜索栏中,您可以搜索感兴趣的主题。
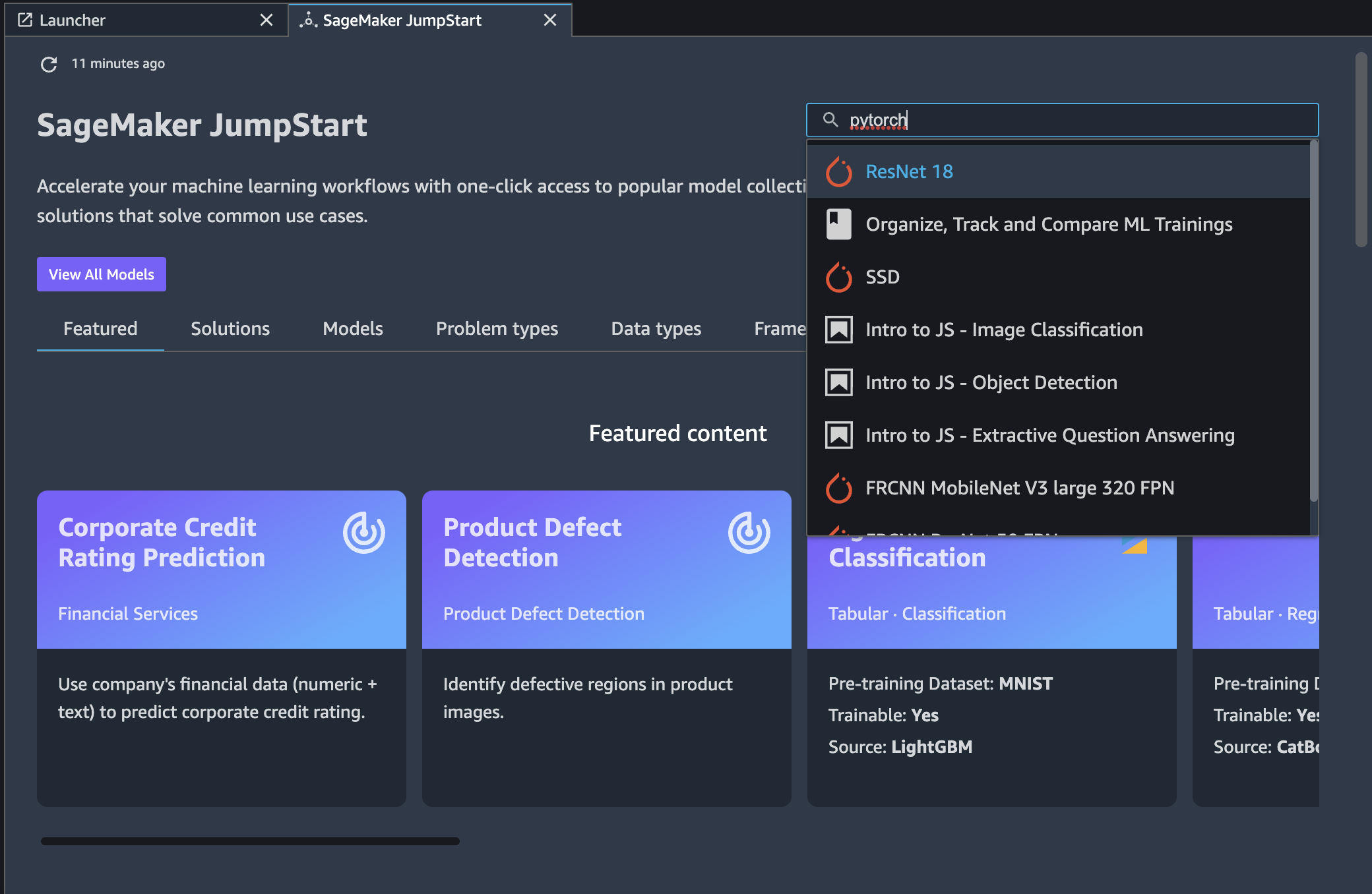
您可以找到 JumpStart 通过使用搜索或浏览搜索面板后面的每个类别来资源:
-
精选— 最新或最常用的解决方案、模型和示例。
-
解决方案— 只需一步即可启动全面的机器学习解决方案 SageMaker 到其他Amazon服务。Select探索所有解决方查看所有可用的解决方案。
模型— 从文本、视觉和表格模型集合中找到适合您需求的模型。您可以按问题类型、数据类型和框架筛选集合。然后,只需一步即可部署和优化预训练的图像分类和物体检测模型。Select探索所有模型查看所有可用型号。
-
资源— 使用示例笔记本、博客和视频教程来学习并开始你的问题类型。
示例笔记本— 运行使用的示例笔记本 SageMaker 诸如竞价型实例训练和对各种模型类型和使用案例的实验等功能。
博客— 阅读由亚马逊托管的机器学习专家的详细信息和解决方案。
视频教程— 观看视频教程 SageMaker 由亚马逊托管的机器学习专家提供的功能和机器学习用例。
方案模板
从 JumpStart 登录页面,获取为常见使用案例设置完整基础架构的解决方案模板。
当你选择解决方案模板时, JumpStart 显示解决方案的描述和启动按钮。选择的时候启动,JumpStart 创建了运行解决方案所需的所有资源。这包括培训和模型托管实例。
晚于 JumpStart 启动解决方案, JumpStart 显示打开笔记本按钮。选择按钮以使用提供的笔记本电脑并探索解决方案的功能。当生成工件时、在启动期间或运行提供的笔记本之后,它们将列在生成的构件表。你可以使用垃圾图标删除单个工件 (
 )。您可以通过选择删除解决方案的所有资源删除解决方案资.
)。您可以通过选择删除解决方案的所有资源删除解决方案资.
以下是可用的解决方案模板的完整列表:
| 使用案例 | 解决方案名称 | 描述 | 开始使用 |
|---|---|---|---|
| 时间序列预测 | 需求预测 | 使用三种先进的时间序列预测算法对多变量时间序列数据的需求进行预测:lstNet |
|
| 预测信用率 | 企业信用评级预测 | 使用多模式(长文本和表格式)机器学习进行高质量信用预测Amazon AutoGLON 表格 |
GitHub” |
| | 基于图表的信用评分 | 使用表格数据和企业网络预测企业信用评级,通过培训图神经网络 GraphSage |
在亚马逊中查找 SageMaker Studio。 |
| | 解释信用决策 | 预测信用申请中的信用违约并使用lightgBm |
|
| 从文档中提取数据并进行分析 | 隐私情绪分类 | 匿名处理文本 |
|
| | 文档摘要、实体和关系提取 | 使用变形金刚 |
|
| | 识别手写 | 通过训练来识别图像中的手写文字对象检测模型 |
GitHub” |
| | 在表格记录中填写缺少的值 | 通过训练 a 填充表格记录中的缺失值SageMaker Autopilot |
|
| 欺诈侦测 | 检测恶意用户和交易 | 使用自动检测交易中潜在的欺诈活动SageMaker XGBoost使用过度采样技术合成少数群体过采样 |
|
| | 使用深图库进行金融交易中的欺诈检测 | 通过培训图形卷积网络 |
|
| 预测性维护 | 车队的预测性维护 | 通过卷积神经网络模型,使用车辆传感器和维护信息预测车队故障。 | |
| | 制造业的预测性维护 | 通过训练一个来预测每个传感器的剩余使用寿命堆叠双向 LSTM 神经网络 |
|
| 计算机视觉 | 图片中的商品缺陷检测 | 通过训练和识别商品图片中的缺陷区域对象检测模型 |
|
| 预测流失 | 使用文本预测流失 | 使用数字、分类和文本要素预测流失BERT 编码器 |
|
| 个性化推荐 | 具有深层图库的身份图中的实体解析 | 通过对在线广告进行跨设备实体链接,通过培训图形卷积网络 |
|
| | 购买模型 | 通过培训一个预测客户是否会进行购买SageMaker XGBoost模型。 | |
| 强化学习 | Battlesnake AI 比赛的强化学习 | 为训练和推理提供强化学习工作流程BattleSnake |
|
| | Procgen 挑战的分布式强化学习 | 分布式强化学习入门套件NeurIPS 2020 年 Progen |
GitHub” |
模型
JumpStart 支持十五种最受欢迎的问题类型的模型。在受支持的问题类型中,Vision 和 NLP 相关类型共有 13 种。有八种问题类型支持增量训练和微调。有关增量训练和超参数调整的更多信息,请参阅SageMaker 自动模型优化。 JumpStart 还支持四种常见的表格数据建模算法。
你可以从 JumpStart 工作室中的着陆页。选择模型时,模型详细信息页面将提供有关该模型的信息,您可以通过几个步骤来训练和部署模型。描述部分描述了可以对模型执行的操作、预期的输入和输出类型以及微调模型所需的数据类型。
您还可以通过编程方式使用模型SageMaker Python SDK
下表总结了问题类型列表以及指向其示例 Jupyter 笔记本的链接。有关的完整列表 JumpStart 模型,请参阅JumpStart 可用型号表
| 问题类型 | 通过预训练的模型支持推理 | 可在自定义数据集上训练 | 支持的框架 | 示例笔记本 |
|---|---|---|---|---|
| 图像分类 | 是 | 是 |
PyTorch,TensorFlow |
|
| 对象检测 | 是 | 是 | PyTorch、TensorFlow、MxNet | |
| 语义分割 | 是 | 是 | MXNet | |
| 实例分段 | 是 | 是 | MXNet | |
| 嵌入图像 | 是 | 否 | TensorFlow,MxNet | |
| 文本分类 | 是 | 是 | TensorFlow | |
| 句子对分类 | 是 | 是 | TensorFlow,拥抱脸 | |
| 解答的问题 | 是 | 是 | PyTorch | |
| 命名实体识别 | 是 | 否 | 拥抱面部 | |
| 文本总结 | 是 | 否 | 拥抱面部 | |
| 文本生成 | 是 | 否 | 拥抱面部 | |
| 机器翻译 | 是 | 否 | 拥抱面部 | |
| 文本嵌入 | 是 | 否 | TensorFlow,MxNet | |
| 表格分类 | 是 | 是 | lightgBm、catBoost、xgBoost、线性学习者 | |
| 表格回归 | 是 | 是 | lightgBm、catBoost、xgBoost、线性学习者 |
部署模型
当你从 JumpStart 部署模型时, SageMaker 托管模型并部署您可用于推理的终端节点。 JumpStart 还提供了一个示例笔记本,您可以在部署模型后用于访问模型。
模型部署配置
选择模型后,部署模型窗格打开。选择部署配置来配置模型部署。

部署模型的默认实例类型取决于模型。实例类型是运行培训作业的硬件。在下面的示例中,ml.g4dn.xlarge实例是此特定 BERT 模型的默认值。
您还可以更改终端节点名称.
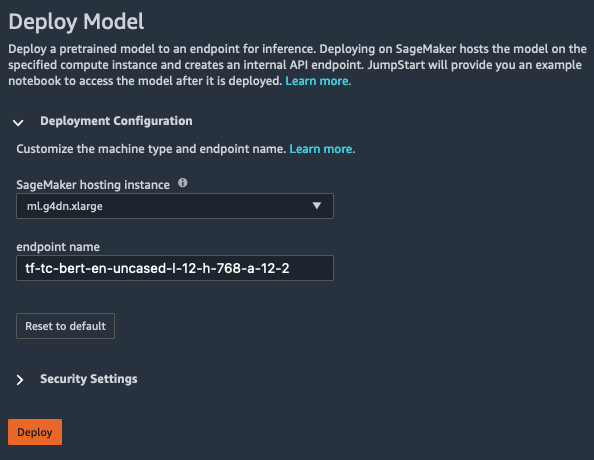
选择安全设置指定Amazon Identity and Access Management(IAM) 角色、Amazon Virtual Private Cloud (Amazon VPC) 和模型的加密密钥。
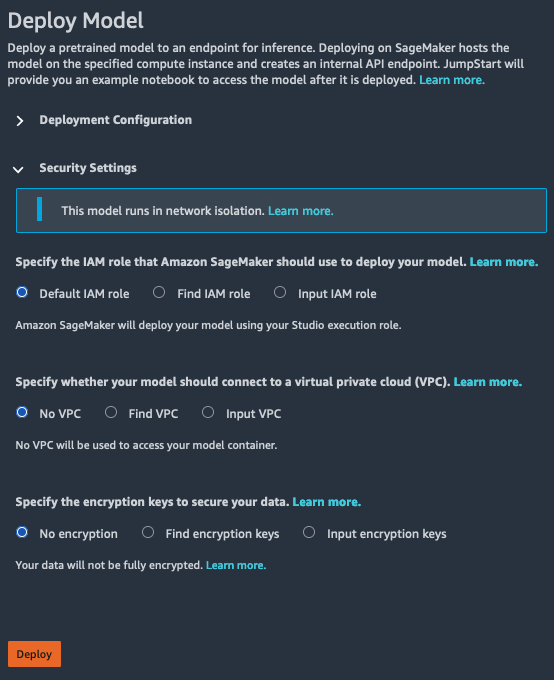
模型部署安全
使用 JumpStart 部署模型时,您可以为该模型指定 IAM 角色、Amazon VPC 和加密密钥。如果未为这些条目指定任何值:默认 IAM 角色是您的 Studio 运行时角色;使用默认加密;不使用任何 Amazon VPC。
IAM 角色
您可以选择作为培训作业和托管作业的一部分传递的 IAM 角色。 SageMaker 使用此角色访问训练数据和模型工件。如果您未选择 IAM 角色, SageMaker 使用 Studio 运行时角色部署模型。有关 IAM 角色的更多信息,请参阅适用于 Amazon SageMaker 的 Identity and Access Management.
您传递的角色必须有权访问模型所需的资源,并且必须包括以下所有内容。
对于训练作业:CreateTrainingJob API:执行角色权限.
对于托管工作:CreateModel API:执行角色权限.
您可以缩小以下每个角色中授予的 Amazon S3 权限的范围。要执行此操作,请使用 Amazon Simple Storage Service (Amazon S3) 存储桶的 Amazon Resource Name (ARN) 和 JumpStart Amazon S3 存储桶。
{ "Effect": "Allow", "Action": [ "s3:GetObject", "s3:PutObject", "s3:ListMultipartUploadParts" ], "Resources": [ "arn:aws:s3:<region>::bucket/jumpstart-cache-prod-<region>/*", "arn:aws:s3:<region>:<account>:bucket/*", ] },{ "Effect": "Allow", "Action": [ "s3:ListBucket", ], "Resources": [ "arn:aws:s3:<region>::bucket/jumpstart-cache-prod-<region>", "arn:aws:s3:<region>:<account>:bucket", ]
查找 IAM 角色
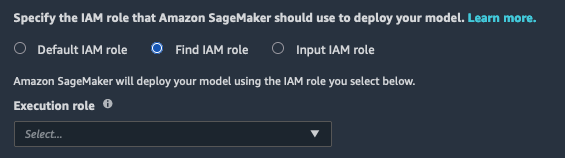
如果选择此选项,则必须从下拉列表中选择一个现有 IAM 角色。
输入 IAM 角色
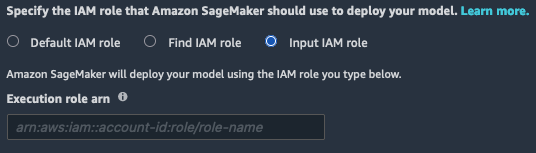
如果选择此选项,则必须为现有 IAM 角色手动输入 ARN。如果您的 Studio 运行时角色或 Amazon VPC 阻止iam:list* 调用时,您必须使用此选项才能使用现有 IAM 角色。
Amazon VPC
全部 JumpStart 模型在网络隔离模式下运行。创建模型容器之后,不能再进行调用。您可以选择作为培训作业和托管工作的一部分传递的 Amazon VPC。 SageMaker 使用此 Amazon VPC 从 Amazon S3 存储桶中推送和提取资源。此 Amazon VPC 不同于限制从您的 Studio 实例访问公共互联网的亚马逊 VPC。有关 Studio Amazon VPC 的更多信息,请参阅Connect (连接) SageMaker VPC 中的 Studio 笔记本电脑到外部资源.
您传递的 Amazon VPC 不需要访问公共互联网,但确实需要访问 Amazon S3。Amazon S3 的 Amazon VPC 终端节点必须允许至少访问模型所需的以下资源。
{ "Effect": "Allow", "Action": [ "s3:GetObject", "s3:PutObject", "s3:ListMultipartUploadParts" ], "Resources": [ "arn:aws:s3:<region>::bucket/jumpstart-cache-prod-<region>/*", "arn:aws:s3:<region>:<account>:bucket/*", ] },{ "Effect": "Allow", "Action": [ "s3:ListBucket", ], "Resources": [ "arn:aws:s3:<region>::bucket/jumpstart-cache-prod-<region>", "arn:aws:s3:<region>:<account>:bucket", ]
如果您没有选择亚马逊 VPC,则不会使用任何亚马逊 VPC。
查找 VPC
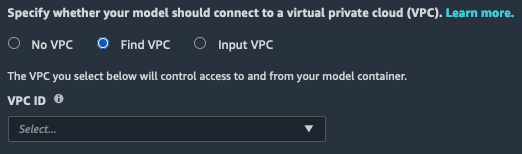
如果选择此选项,则必须从下拉列表中选择现有的 Amazon VPC。选择 Amazon VPC 后,您必须为您的 Amazon VPC 选择子网和安全组。有关子网和安全组的更多信息,请参阅VPC 和子网的概述.
输入 VPC
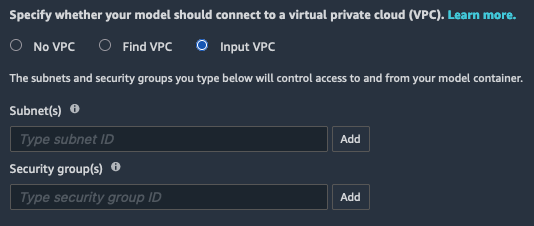
如果选择此选项,则必须手动选择组成 Amazon VPC 的子网和安全组。如果您的 Studio 运行时角色或 Amazon VPC 阻止ec2:list*调用时,您必须使用此选项来选择子网和安全组。
加密密密钥
你可以选择Amazon KMS作为培训工作和托管工作的一部分传递的关键。 SageMaker 使用此密钥加密容器的 Amazon EBS 卷,并使用 Amazon S3 中重新打包的模型来托管作业和培训作业的输出。有关 的更多信息Amazon KMS钥匙,请参阅Amazon KMS密钥.
您传递的密钥必须信任您传递的 IAM 角色。如果您没有指定 IAM 角色,则Amazon KMS密钥必须信任你的 Studio 运行时角色。
如果你没有选择Amazon KMS键, SageMaker 为 Amazon EBS 卷中的数据和 Amazon S3 工件提供默认加密。
查找加密密钥
如果选择此选项,则必须选择现有的Amazon KMS从下拉列表中显示密钥。
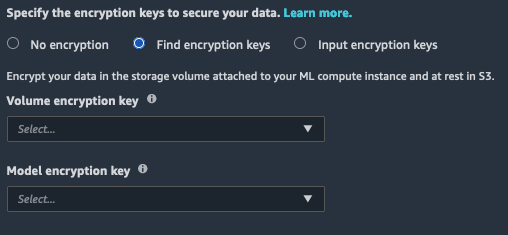
输入加密密密钥
如果选择此选项,则必须手动输入Amazon KMS钥匙。如果您的 Studio 执行角色或 Amazon VPC 阻止kms:list* 呼叫,你必须使用此选项来选择现有Amazon KMS钥匙。
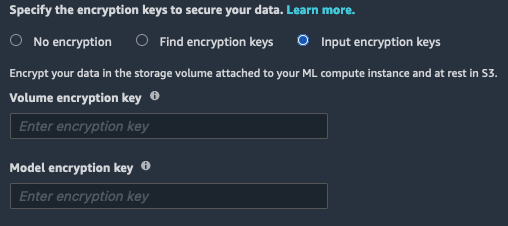
微调模型
微调在新数据集上训练预先训练的模型,而无需从头开始训练。这个过程也称为转移学习,可以生成具有较小数据集和更短训练时间的准确模型。
微调数据源
当您微调模型时,您可以使用默认数据集或选择位于 Amazon S3 存储桶中的自己的数据。
要浏览可用的存储桶,请选择查找 S3 存储桶. 这些存储桶受用于设置 Studio 帐户的权限的限制。您还可以通过选择以下方式指定 Amazon S3 URI输入 Amazon S3 存储桶位置.
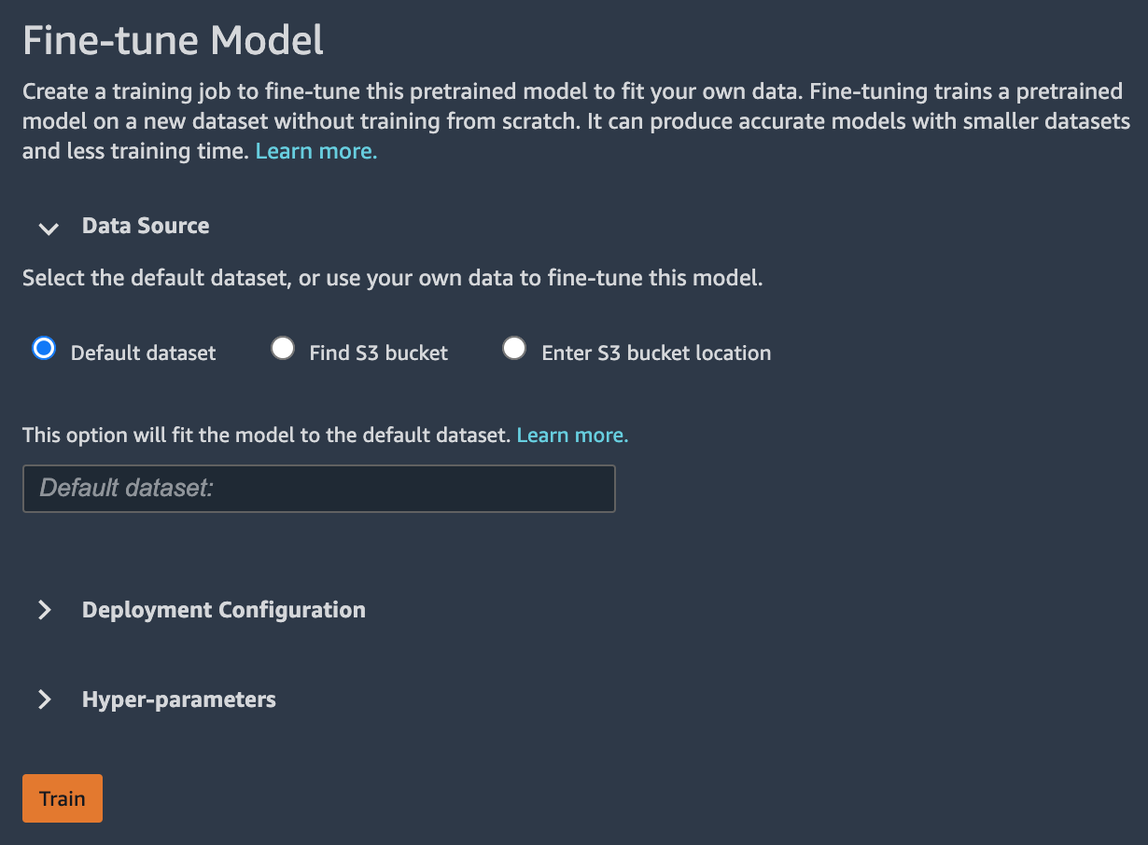
要了解如何格式化存储桶中的数据,请选择了解更多. 模型的描述部分包含有关于输入和输出的详细信息。
对于文本模型:
-
存储桶必须有 data.csv 文件。
-
第一列必须是类别标签的唯一整数。例如:
1、2、3、4、n -
第二列必须是字符串。
-
第二列应包含与模型的类型和语言匹配的相应文本。
对于视觉模型:
-
存储桶的子目录必须与类数相同。
-
每个子目录都应以 .jpg 格式包含属于该类的图像。
Amazon S3 存储桶必须位于同一位置Amazon Web Services 区域你跑的地方 SageMaker 因为 Studio SageMaker 不允许跨区域请求。
微调部署配置
推荐使用 p3 系列作为深度学习训练最快的系列,建议用于微调模型。下图显示了每种实例类型中 GPU 的数量。还有其他可供选择的选项,包括 p2 和 g4 实例类型。
| 实例类型 | GPU |
| p3.2xlarge | 1 |
| p3.8xlarge | 4 |
| p3.16xlarge | 8 |
| p3dn.24xlarge | 8 |
超参数
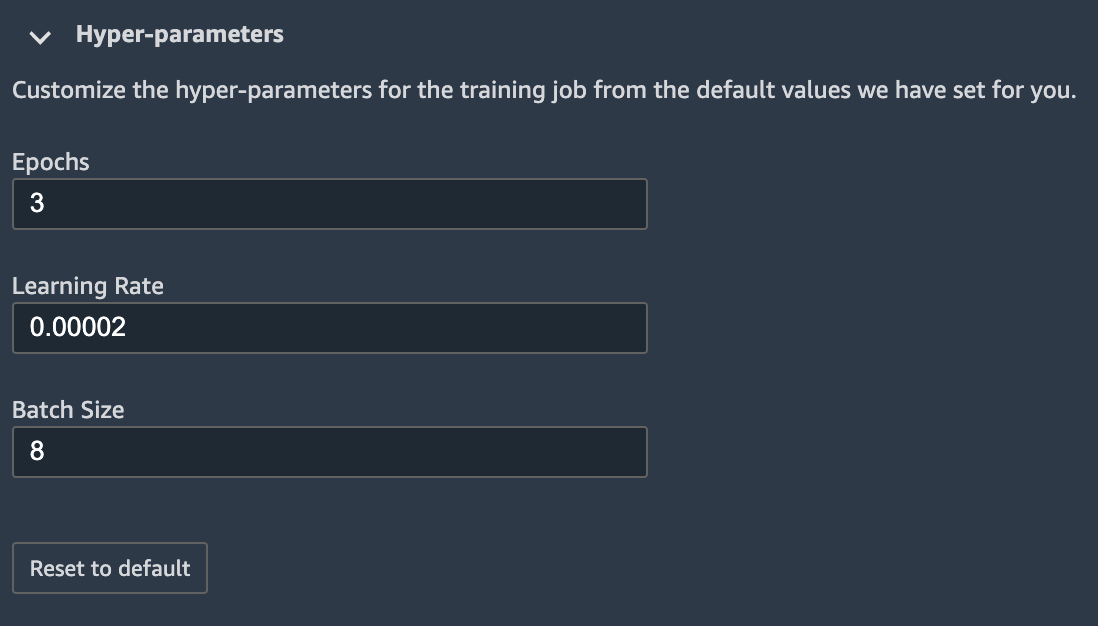
您可以自定义用于微调模型的训练作业的超参数。
如果您在不更改超参数的情况下将默认数据集用于文本模型,则会得到几乎相同的模型。对于视觉模型,默认数据集与用于训练预训练模型的数据集不同,因此您的模型因此不同。
您有以下超参数选项:
-
Epoch— 一个时代是一个循环遍历整个数据集。多个时间间隔完成一个批次,多个批次最终完成了一个纪元。运行多个纪元,直到模型的准确度达到可接受的水平,或者当错误率降至可接受的水平以下时。
-
Learning rate (学习速率)— 值应在各个纪元之间更改的金额。随着模型的优化,其内部权重将被推动,并检查错误率以确定模型是否有所改善。典型的学习率为 0.1 或 0.01,其中 0.01 是一个小得多的调整,可能会导致训练需要很长时间才能收敛,而 0.1 要大得多,可能会导致训练过度。这是为训练模型而可能会调整的主要超参数之一。请注意,对于文本模型,较小的学习率(BERT 为 5e-5)可以生成更准确的模型。
-
批处理大小— 将在每个时间间隔内从数据集中选择的记录数,以发送到 GPU 进行训练。
在图像示例中,每个 GPU 可能会发送 32 张图像,所以 32 张是批量大小。如果您选择具有多个 GPU 的实例类型,则该批次除以 GPU 的数量。建议的批量大小因您使用的数据和模型而异。例如,优化图像数据的方式与处理语言数据的方式不同。
在部署配置部分的实例类型图表中,您可以看到每种实例类型的 GPU 数量。从标准推荐的批量大小开始(例如,对于视觉模型,32)。然后,将此值乘以您选择的实例类型中的 GPU 数量。例如,如果您使用的是
p3.8xlarge,这将是 32(批量大小)乘以 4(GPU),总计 128 个,因为批量大小会根据 GPU 的数量进行调整。对于 BERT 这样的文本模型,请尝试从 64 的批次大小开始,然后根据需要减少。
训练输出
当微调过程完成后, JumpStart 提供有关模型的信息:父模型、培训作业名称、培训作业亚马逊资源名称 (ARN)、培训时间和输出路径。输出路径是您可以在 Amazon S3 存储桶中找到新模型的位置。文件夹结构使用您提供的模型名称,模型文件位于/output子文件夹,它总是被命名model.tar.gz.
示例:s3://bucket/model-name/output/model.tar.gz