本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
Tensor 并行度的工作原理
Tensor 并行性发生在nn.Modules; 它将模型中的特定模块划分为张量 parallel 等级。这是对现有的分区的补充一组模块在管道并行机制中使用。
当一个模块通过张量并行分区时,它的向前和向后传播都是分布的。该库处理必要的跨设备通信,以实现这些模块的分布式执行;这些模块分布在多个数据 parallel 等级中。与传统的工作负载分布相反,每个数据 parallel 排名都是不当使用库的张量并行度时,拥有完整的模型副本。相反,除了未分发的整个模块之外,每个数据 parallel 排名可能只有分布式模块的一个分区。
示例:考虑跨数据并 parallel 排名的张量并行度,其中数据并行度为 4,张量并行度为 2。假设在对模块集进 parallel 分区之后,有一个包含以下模块树的数据并行组。
A ├── B | ├── E | ├── F ├── C └── D ├── G └── H
假设模块 B、G 和 H 支持张量并行性,此模型的张量 parallel 分区的一个可能结果可能是:
dp_rank 0 (tensor parallel rank 0): A, B:0, C, D, G:0, H dp_rank 1 (tensor parallel rank 1): A, B:1, C, D, G:1, H dp_rank 2 (tensor parallel rank 0): A, B:0, C, D, G:0, H dp_rank 3 (tensor parallel rank 1): A, B:1, C, D, G:1, H
每行代表存储在其中的一组模块dp_rank,以及符号X:y表示y模块的第一部分X. 请注意以下几点:
-
分区发生在数据并行等级的子集之间进行,我们称之为
TP_GROUP,而不是整个DP_GROUP,以便在其中复制确切的模型分区dp_rank0 和dp_rank2,以及类似的横跨dp_rank1 和dp_rank3. -
模块
E和F不再是模型的一部分,因为他们的父模块B已分区,并且任何通常属于其中一部分的执行E和F发生在(已分区)B模块。 -
尽管
H支持张量并行性,在本例中它不是分区的,这突出了是否对模块进行分区取决于用户的输入。一个模块受张量并行性支持这一事实并不一定意味着它被分区。
库如何使张量并行性适应 PyTorchnn.Linear模块
当对数据并行等级执行张量 parallel 度时,将在张量并 parallel 设备之间划分参数、渐变和优化器状态的子集对于已分区的模块. 对于其余模块,张量 parallel 器件以常规的数据并行方式运行。要执行分区模块,设备首先收集必要的部分所有数据示例跨同一张量并行度组中的对等设备。然后对所有这些数据样本执行模块的局部部分,然后再执行另一轮同步,这两轮同步结合了每个数据样本的输出部分,并将组合的数据样本返回到数据样本最初源自的 GPU。下图显示了分区上此过程的示例。nn.Linear模块。
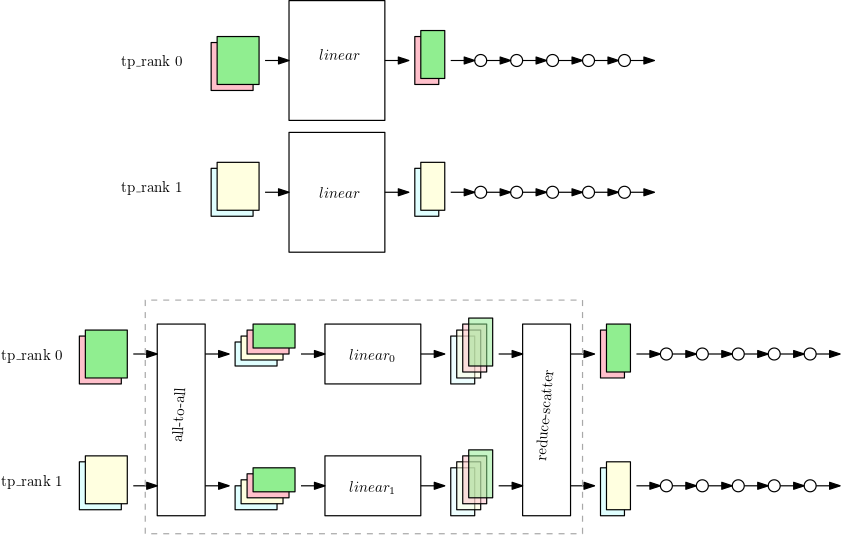
第一张图显示了一个带有大号的小型模型nn.Linear模块的数据并行度超过两个张量并行度等级。这些区域有:nn.Linear模块被复制到两个 parallel 的等级中。
第二张图显示了在拆分时应用于较大模型的张量并行度nn.Linear模块。每个tp_rank拥有线性模块的一半,以及其余操作的全部。在线性模块的执行过程中,每个tp_rank收集所有数据样本中的相关一半并将其传递给他们的一半nn.Linear模块。结果需要减少分散(以求和作为缩减运算),以便每个等级都有自己的数据样本的最终线性输出。模型的其余部分以典型的数据 parallel 方式运行。