本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
排名机制
本节介绍了模型并行度的排名机制如何与张量并行性一起工作。这是从排名基础smp.tp_rank()为了张量 parallel 等级、smp.pp_rank()为了管道 parallel 排名, 和smp.rdp_rank()为了减少数据 parallel 排名. 相应的沟通流程组包括张量 parallel 组(TP_GROUP),管道 parallel 组(PP_GROUP),以及减少的数据 parallel 组(RDP_GROUP)。这些组的定义如下:
-
张量 parallel 组 (
TP_GROUP) 是数据 parallel 组的一个均匀可分割的子集,模块的张量 parallel 分布发生在该组上。当管道并行度为 1 时TP_GROUP和相同模型 parallel 组(MP_GROUP)。 -
管道 parallel 组 (
PP_GROUP) 是管道并行性发生的一组流程。当张量并行度度为 1 时PP_GROUP和相同MP_GROUP. -
减少的数据 parallel 组 (
RDP_GROUP) 是一组进程,它们保存相同的管道并行分区以及相同的张量并行分区,并在它们之间执行数据并行处理。这被称为减少的数据 parallel 组,因为它是整个数据并行度组的一个子集,DP_GROUP. 对于分布在TP_GROUP,渐变allreduce操作仅对减少的数据 parallel 组执行,而对于未分布的参数,则为梯度allreduce发生在整个DP_GROUP. -
模型 parallel 组 (
MP_GROUP) 是指集体存储整个模型的一组进程。它由联盟组成PP_GROUP在所有队伍中的 STP_GROUP当前的流程。当张量并行度为 1 时MP_GROUP等同于PP_GROUP. 它也符合现有的MP_GROUP来自以前smdistributed版本。请注意,当前TP_GROUP是当前两者的子集DP_GROUP和最新的MP_GROUP.
要了解有关通信流程 API 的更多信息,请参阅 SageMaker 分布式模型并行度库,请参阅常见 API
下图说明了排名机制、参数分布以及相关的allreduce运算。
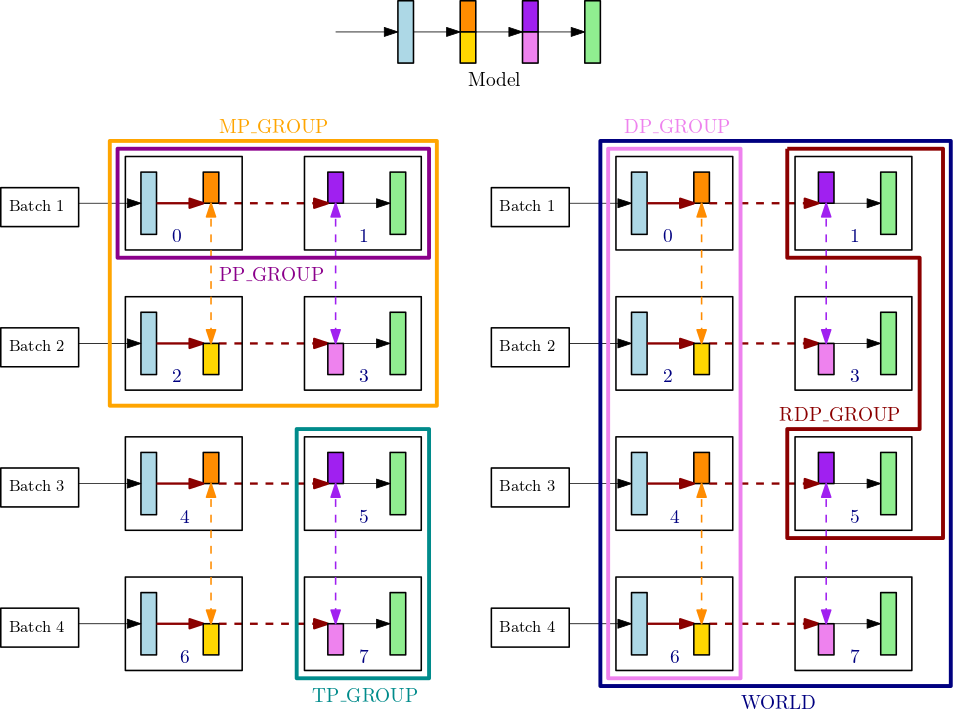
上图说明了具有 8 个 GPU 的节点的进程组,其中张量并行度为 2,管道并行度为 2,数据并行度为 4。第一张图显示了一个具有 4 层的示例模型。在其他图中,4 层模型分布在 4 个 GPU 中,使用管道并行度和张量并行度,其中张量并行度用于中间两层。这些数字是简单的副本,用于说明不同的群体边界线。为跨 GPU 0-3 和 4-7 进行数据并行性复制了分区模型。左下图显示了MP_GROUP、PP_GROUP, 和TP_GROUP. 右下图显示RDP_GROUP、DP_GROUP, 和WORLD在同一组 GPU 上。具有相同颜色的图层和图层切片的渐变为allreduced 共同实现数据并行性。例如,第一层(浅蓝色)获取allreduce横向的运算DP_GROUP,而第二层中的深橙色切片只能获得allreduce内的操作RDP_GROUP它的过程。大胆的暗红色箭头代表张量及其整批TP_GROUP.
GPU0: pp_rank 0, tp_rank 0, rdp_rank 0, dp_rank 0, mp_rank 0 GPU1: pp_rank 1, tp_rank 0, rdp_rank 0, dp_rank 0, mp_rank 1 GPU2: pp_rank 0, tp_rank 1, rdp_rank 0, dp_rank 1, mp_rank 2 GPU3: pp_rank 1, tp_rank 1, rdp_rank 0, dp_rank 1, mp_rank 3 GPU4: pp_rank 0, tp_rank 0, rdp_rank 1, dp_rank 2, mp_rank 0 GPU5: pp_rank 1, tp_rank 0, rdp_rank 1, dp_rank 2, mp_rank 1 GPU6: pp_rank 0, tp_rank 1, rdp_rank 1, dp_rank 3, mp_rank 2 GPU7: pp_rank 1, tp_rank 1, rdp_rank 1, dp_rank 3, mp_rank 3
在此示例中,管道并行性发生在 GPU 对 (0,1); (2,3); (4,5) 和 (6,7) 之间。此外,我们还有数据并行性(allreduce) 在 GPU 0、2、4、6 之间进行,并独立于 GPU 1、3、5、7。Tensor 并行性发生在dp_groups,跨 GPU 对 (0,2); (1,3); (4,6) 和 (5,7)。
请注意,在这种类型的张量并行度下,(the degree of data
parallelism)*(the degree of pipeline parallelism) = (the number of
GPUs).