本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
SageMaker 调试器 xgBoost 培训报告
对于 SageMaker xGBoost 培训作业,请使用调试器CreateexGBoost 报告规则接受关于培训进度和结果的综合培训报告。按照本指南,指定CreateexGBoost 报告在构建 xgBoost 估算器时规则,请使用Amazon SageMaker Python 开发工具包
报告中提供了地块和建议供参考,但不是确定性的。您有责任对信息进行单独评估。
使用调试器 xgBoost 报告规则构建 SageMaker xgBoost 估算器
这些区域有:CreateexGBoost 报告规则从你的训练作业中收集以下输出张量:
-
hyperparameters— 在第一步中保存。 -
metrics— 每 5 个步骤节省损失和准确性。 -
feature_importance— 每 5 个步骤保存一次。 -
predictions— 每 5 个步骤保存一次。 -
labels— 每 5 个步骤保存一次。
输出张量保存在默认的 S3 存储桶中。例如:s3://sagemaker-。<region>-<12digit_account_id>/<base-job-name>/debug-output/
当您为 xGBoost 训练作业构建 SageMaker 估计器时,请指定如下示例代码所示的规则。
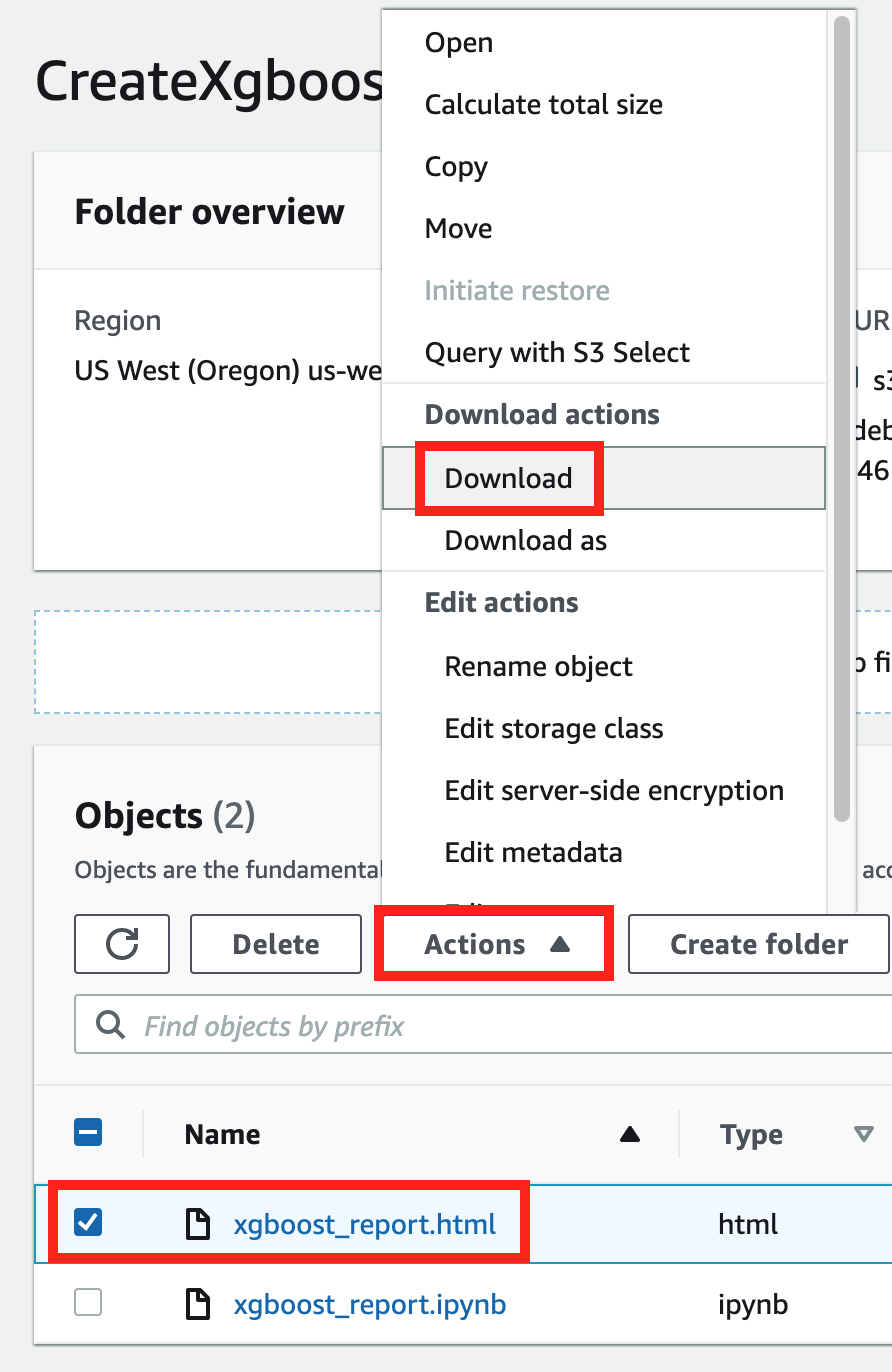
下载调试器 xgBoost 培训报告
在训练作业运行期间或作业完成后使用Amazon SageMaker Python 开发工具包
调试器 xgBoost 培训报告演练
本节指导您完成调试器 xgBoost 培训报告。报告会根据输出张量正则表达式自动聚合,识别二进制分类、多类分类和回归中的训练作业类型。
报告中提供了地块和建议供参考,但不是确定性的。您有责任对信息进行单独评估。
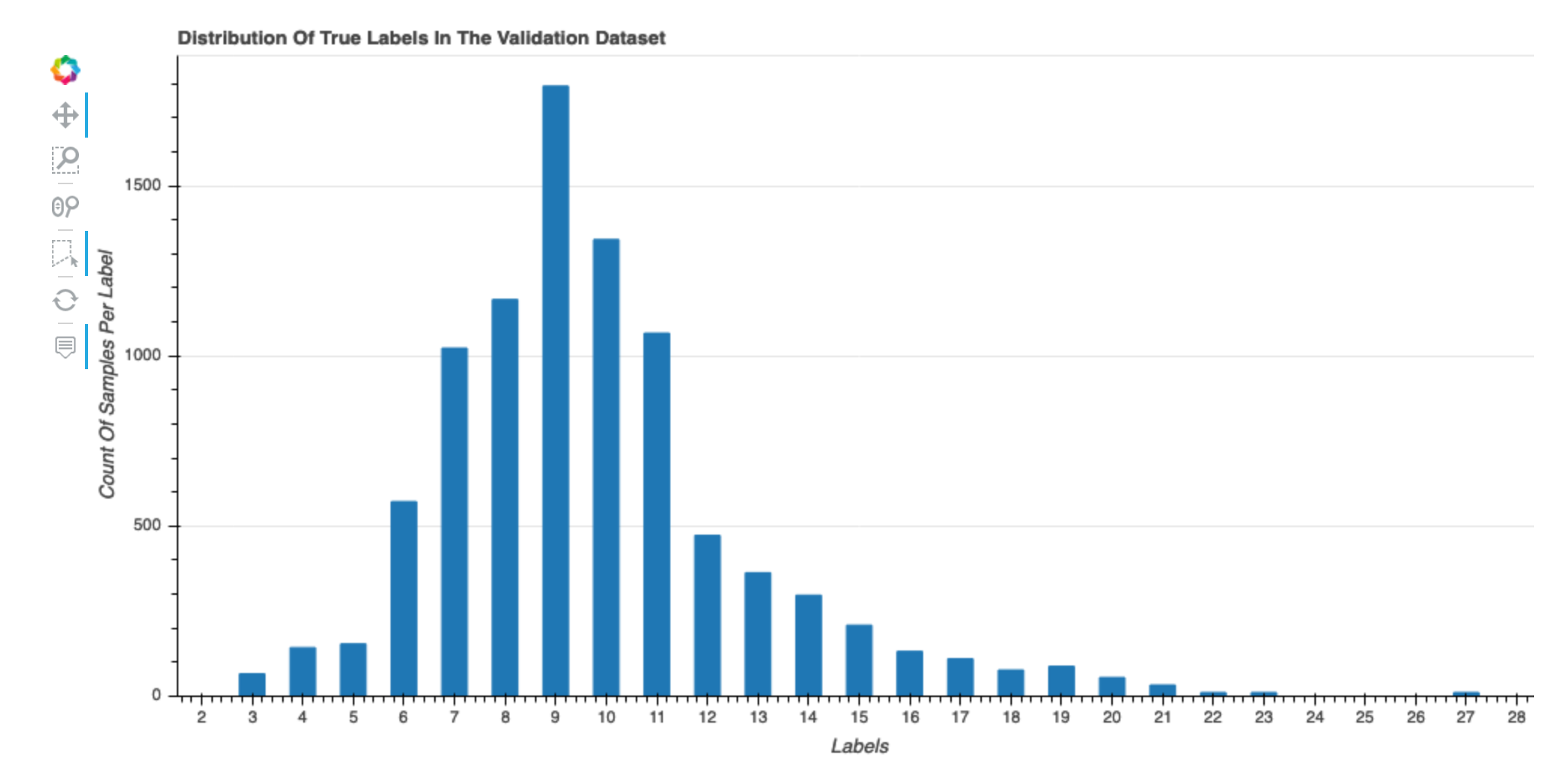
数据集的真实标签的分布
此直方图显示原始数据集中标记类(用于分类)或值(用于回归)的分布情况。数据集中的偏斜可能会导致错误。此可视化适用于以下模型类型:二进制分类、多分类和回归。
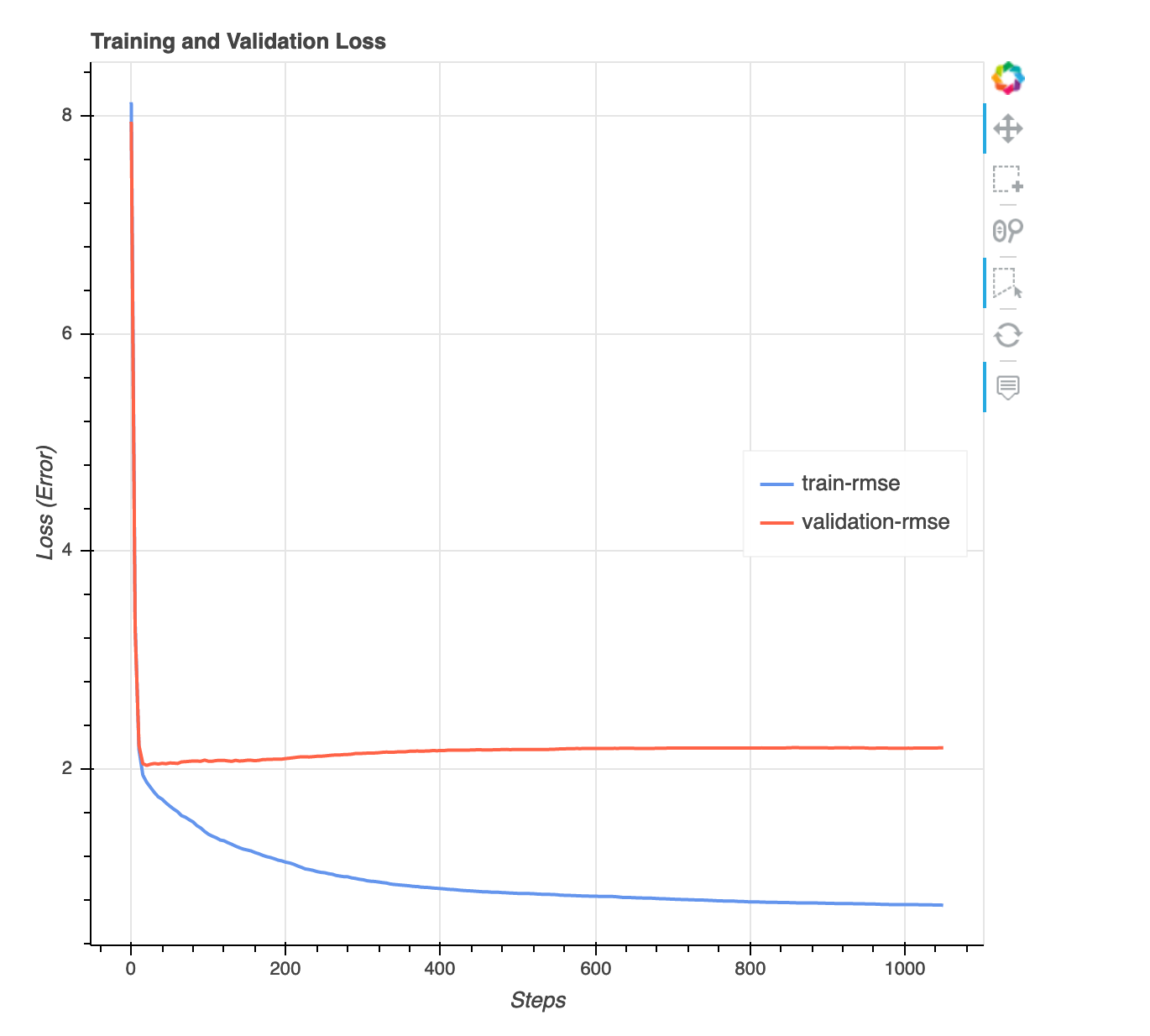
亏损与步长图
这是一个折线图,显示整个训练步骤中训练数据和验证数据丢失的进展。损失是你在目标函数中定义的,例如平方误差。你可以从这个图中衡量模型是过度拟合还是缺陷。此部分还提供见解你可以用它来确定如何解决过度合适和不足的问题。此可视化适用于以下模型类型:二进制分类、多分类和回归。
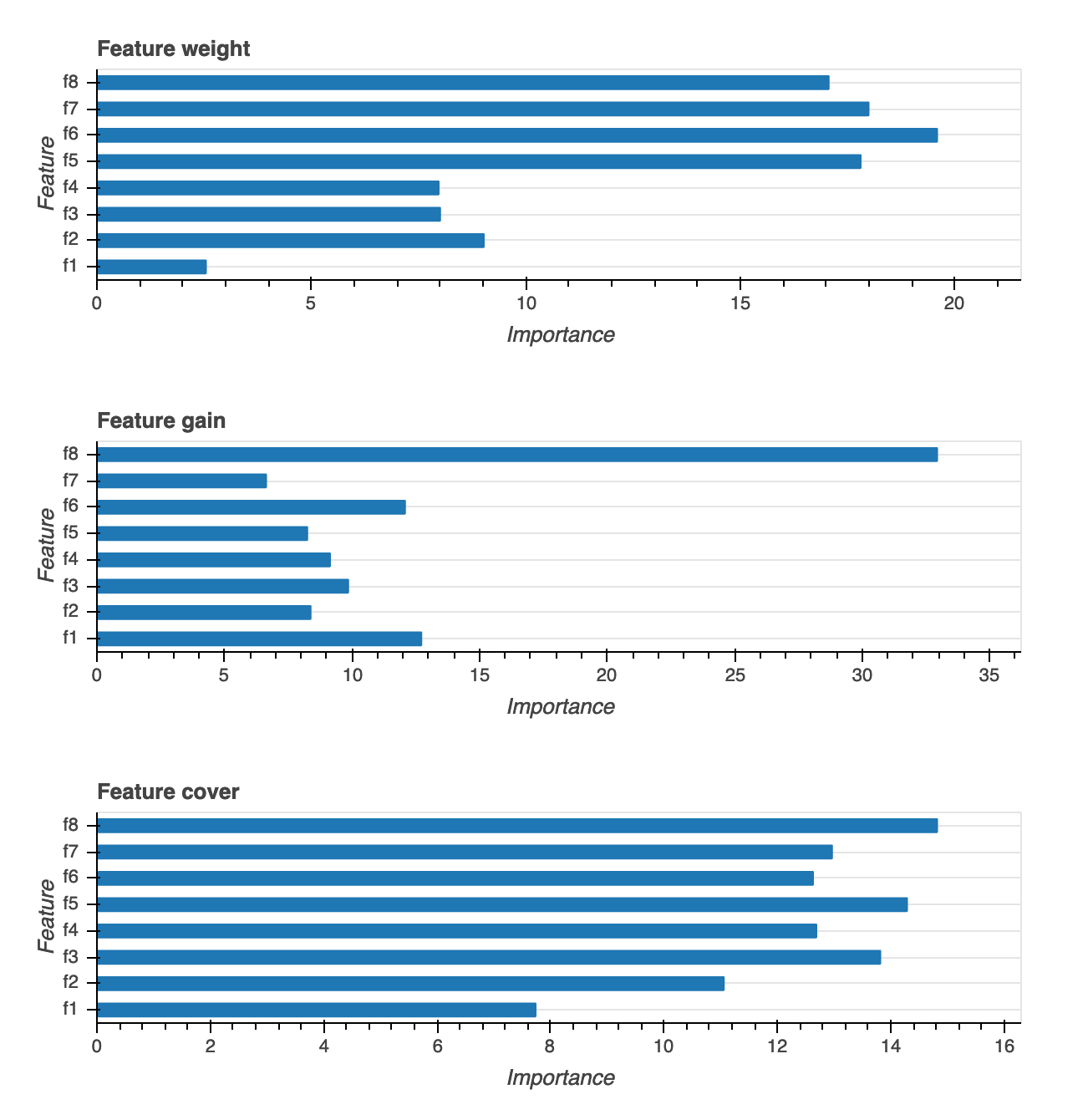
功能重要性
提供了三种不同类型的功能重要性可视化效果:体重、增益和覆盖范围。我们为报告中三者中的每一个提供了详细的定义。要素重要性可视化可帮助您了解训练数据集中的哪些要素对预测作出了贡献。功能重要性可视化可用于以下模型类型:二进制分类、多分类和回归。
混乱矩阵
此可视化仅适用于二进制和多类分类模型。光靠准确度可能不足以评估模型性能。对于某些使用案例,例如医疗保健和欺诈检测,了解假阳性率和误报率也很重要。混淆矩阵为您提供了用于评估模型性能的额外维度。

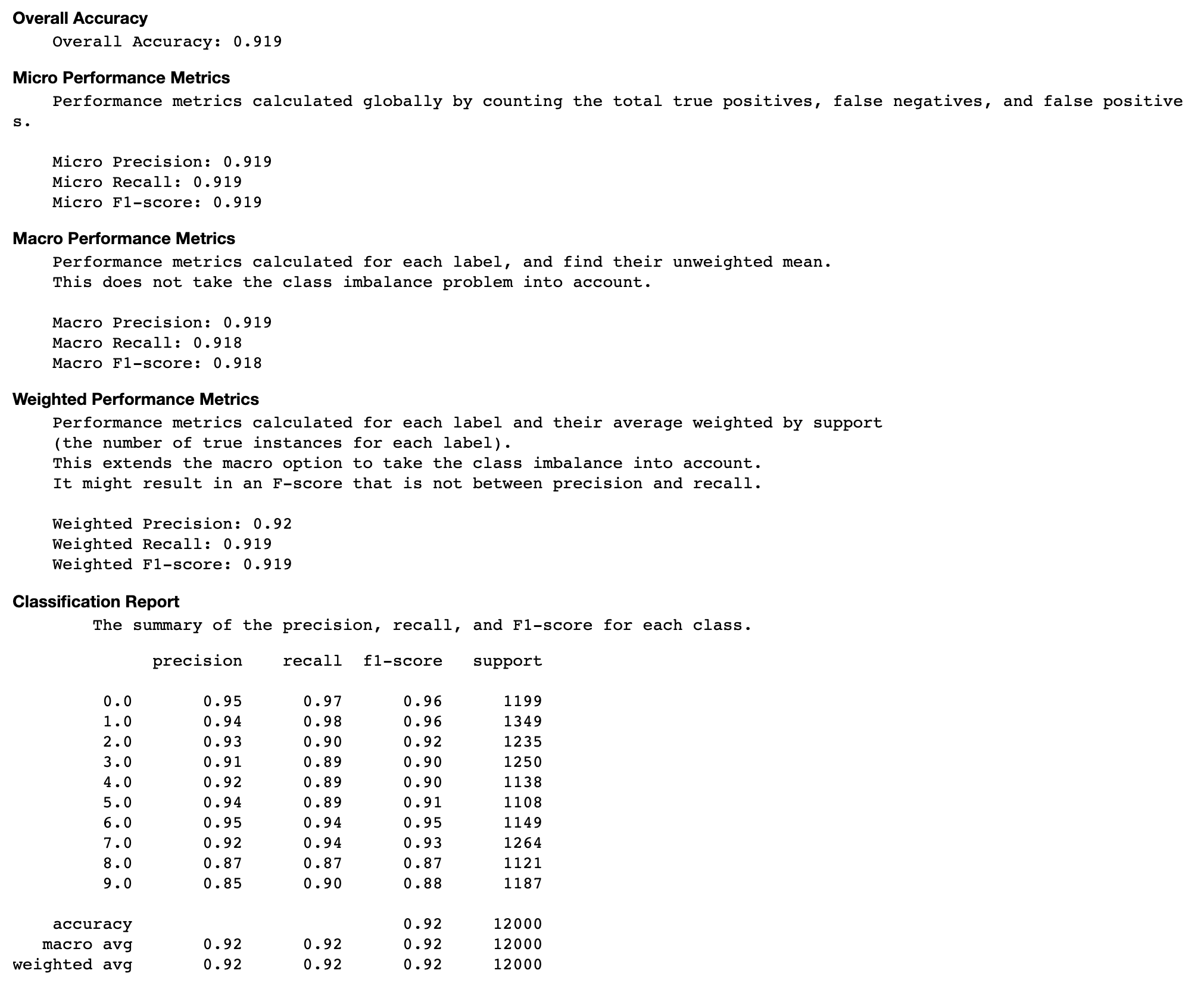
混乱矩阵的评估
本节为您提供了有关模型精度、召回和 F1 分数的微观、宏观和加权指标的更多见解。
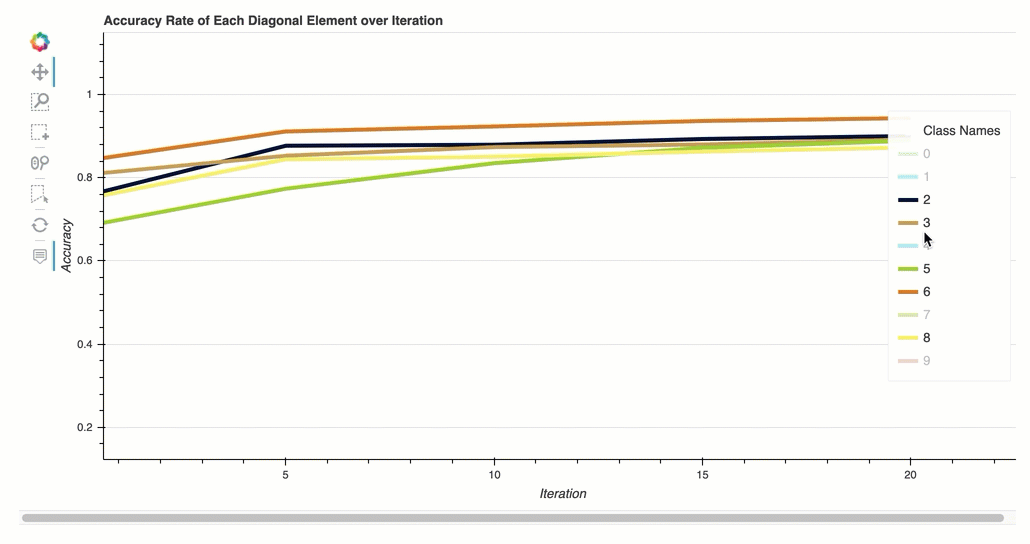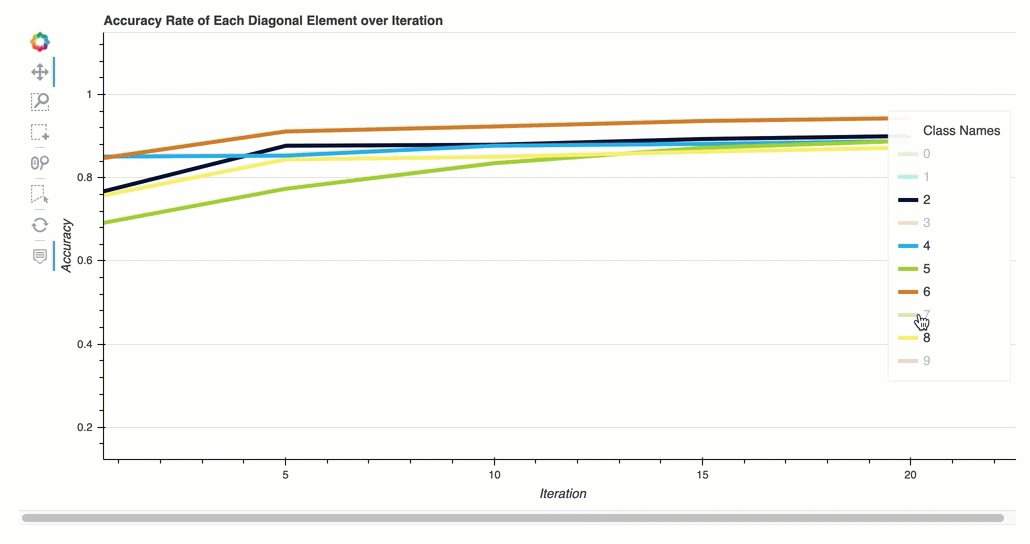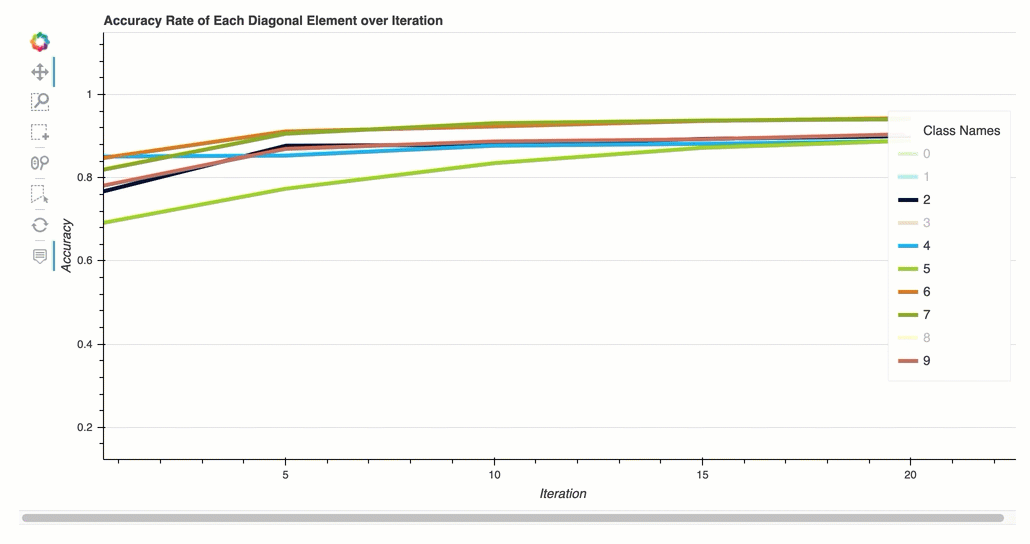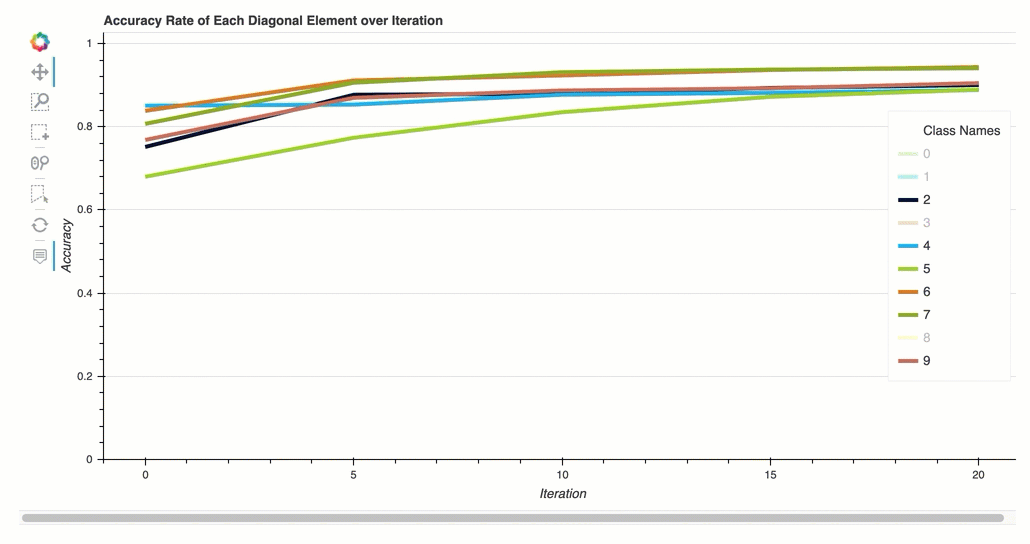
迭代中每个对角线元素的准确率
此可视化仅适用于二进制分类和多类分类模型。这是一个折线图,在每个课程的整个训练步骤中绘制混淆矩阵中的对角线值。此图显示了每个课程的准确性在整个训练步骤中的进展情况。你可以从这个情节中识别表现不佳的课程。
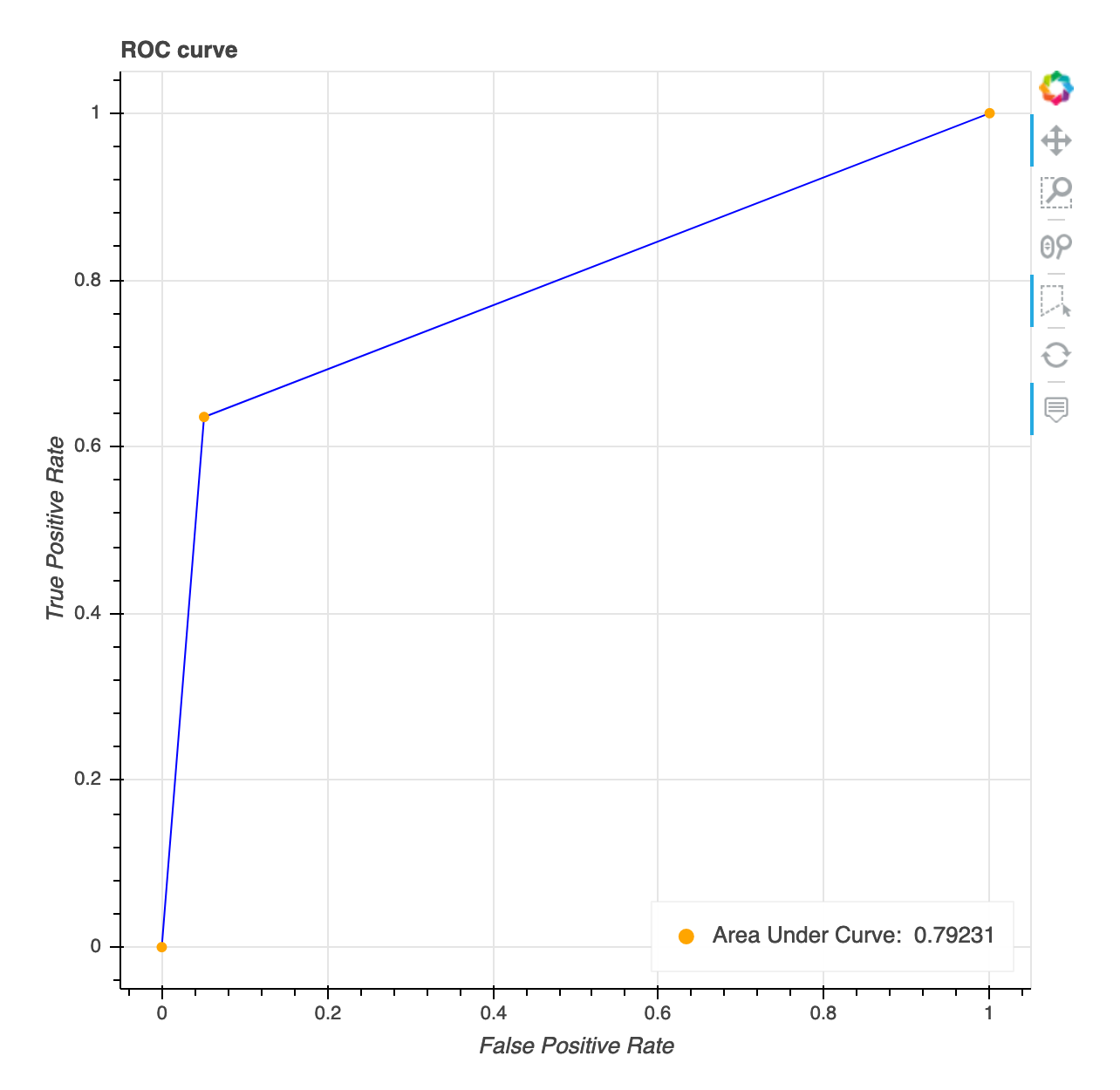
接收器运行特性曲线
此可视化仅适用于二进制分类模型。Receiver 操作特征曲线通常用于评估二进制分类模型的性能。曲线的 y 轴为真正率 (TPF),x 轴为假阳性率 (FPR)。该图还显示曲线下面积 (AUC) 的值。AUC 值越高,分类器的预测性就越高。您还可以使用 ROC 曲线了解 TPR 和 FPR 之间的权衡,并确定用例的最佳分类阈值。可以调整分类阈值以调整模型的行为,以减少多种或另一种类型的错误 (FP/FN)。
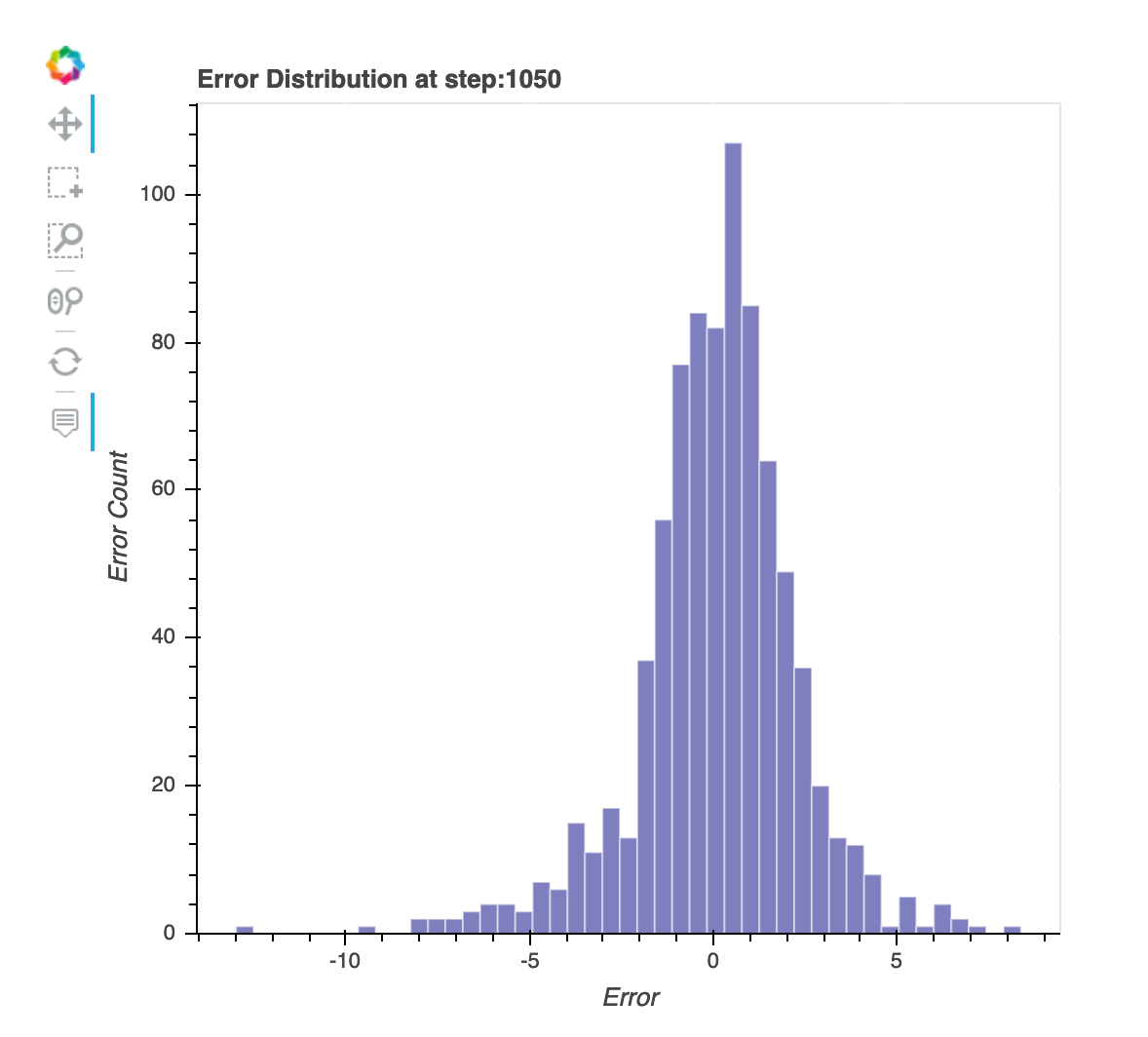
最后保存步骤的残差分布
此可视化是一个柱状图,显示调试器捕获的最后一步中的残余分布。在此可视化中,您可以检查残差分布是否接近以零为中心的正态分布。如果残差偏斜,则您的要素可能不足以预测标注。
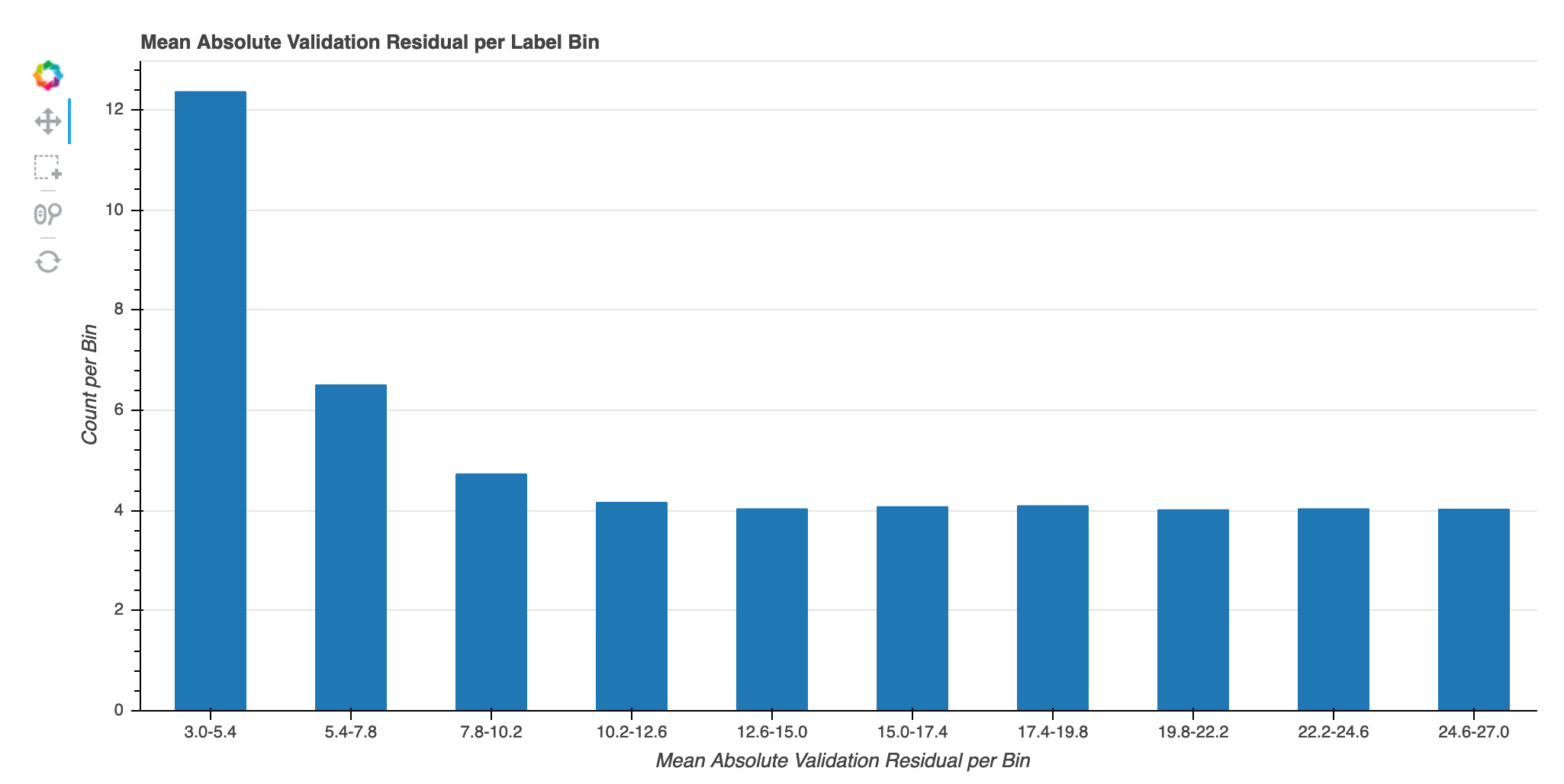
每个标签箱遍历迭代的绝对验证错误
此可视化仅适用于回归模型。实际目标值分为 10 个间隔。此可视化显示了线图中的整个训练步骤中每个时间间隔的验证错误的进展情况。绝对验证误差是验证期间预测与实际差异的绝对值。您可以从此可视化中识别绩效不佳的时间间隔。