本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
创建和使用数据 Wrangler 流
使用 Amazon SageMaker 数据 Wrangler 流程,或数据流,以创建和修改数据准备管道。数据流将数据集、转换和分析连接起来,或者步骤,您可以创建并可用于定义管道。
实例
当您在亚马逊中创建数据 Wrangler 流程时 SageMaker Studio Wrangler 使用 Amazon EC2 实例在流程中运行分析和转换。默认情况下,Data Wrangler 使用 m5.4xlarge 实例。m5 实例是在计算和内存之间实现平衡的通用实例。您可以将 m5 实例用于各种计算工作负载。
Data Wrangler 还为您提供了使用 r5 实例的选项。r5 实例旨在提供处理内存中的大型数据集的快速性能。
我们建议您选择围绕工作负载进行最佳优化的实例。例如,r5.8xlarge 的价格可能比 m5.4xlarge 更高,但 r5.8xlarge 可能会针对您的工作负载进行更好的优化。借助更好的优化实例,您可以以更低的成本在更短的时间内运行数据流。
下表列出了可用于运行 Data Wrangler 流程的实例。
| 标准实例 | vCPU | 内存 |
|---|---|---|
| ml.m5.4xlarge | 16 | 64 GiB |
| ml.m5.8xlarge | 32 | 128 GiB |
| ml.m5.16xlarge | 64 |
256 GiB |
| ml.m5.24xlarge | 96 | 384 GiB |
| r5.4xlarge | 16 | 128 GiB |
| r5.8xlarge | 32 | 256 GiB |
| r5.24xlarge | 96 | 768 GiB |
有关 r5 实例的更多信息,请参阅Amazon EC2 R5 实例
每个 Data Wrangler 流都有一个与之关联的 EC2 实例。您可能有多个流程与单个实例关联。
对于每个流程文件,您可以无缝切换实例类型。如果您切换实例类型,则用于运行流程的实例将继续运行。
要切换流程的实例类型,请执行以下操作。
-
导航到当前正在使用的实例并选择它。下图显示了在哪里选择实例。
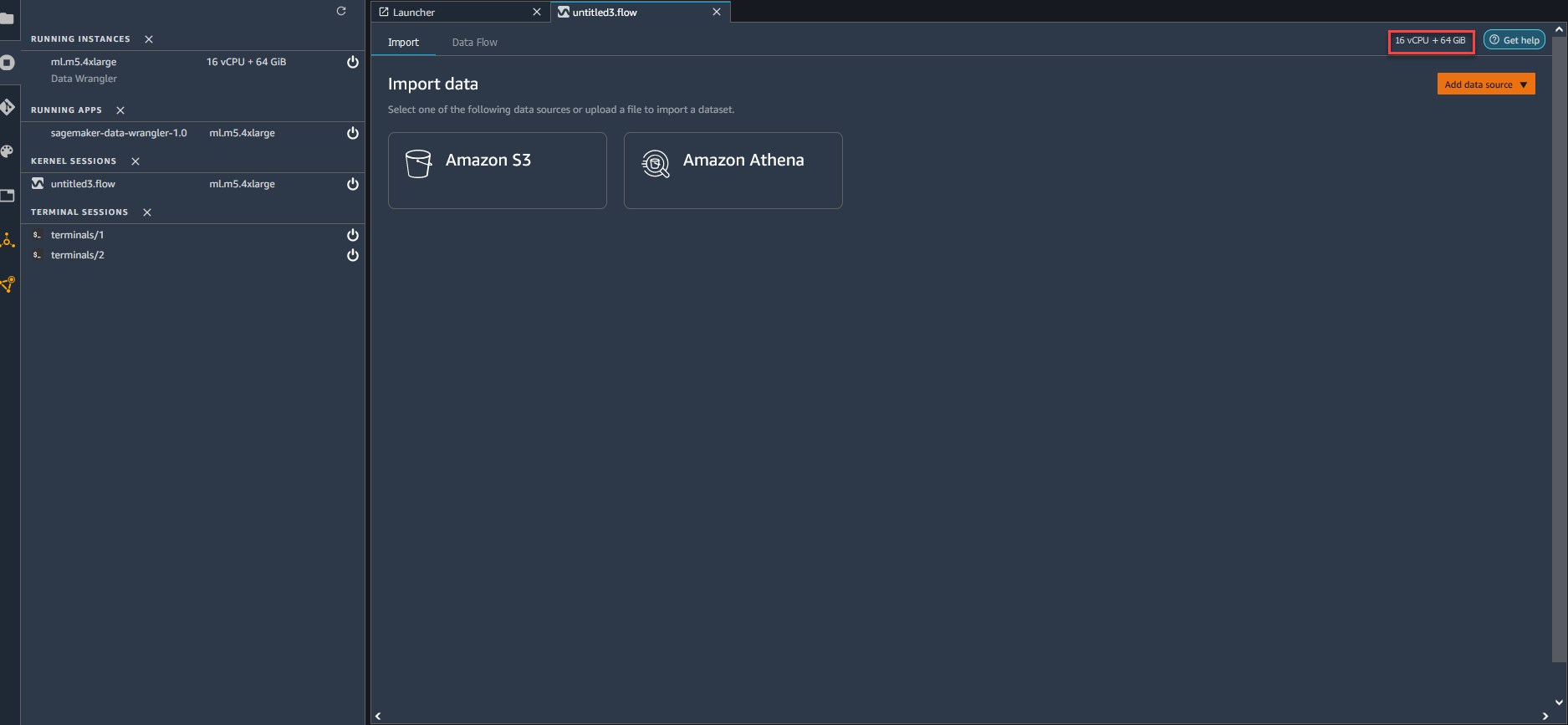
-
选择要使用的实例类型。
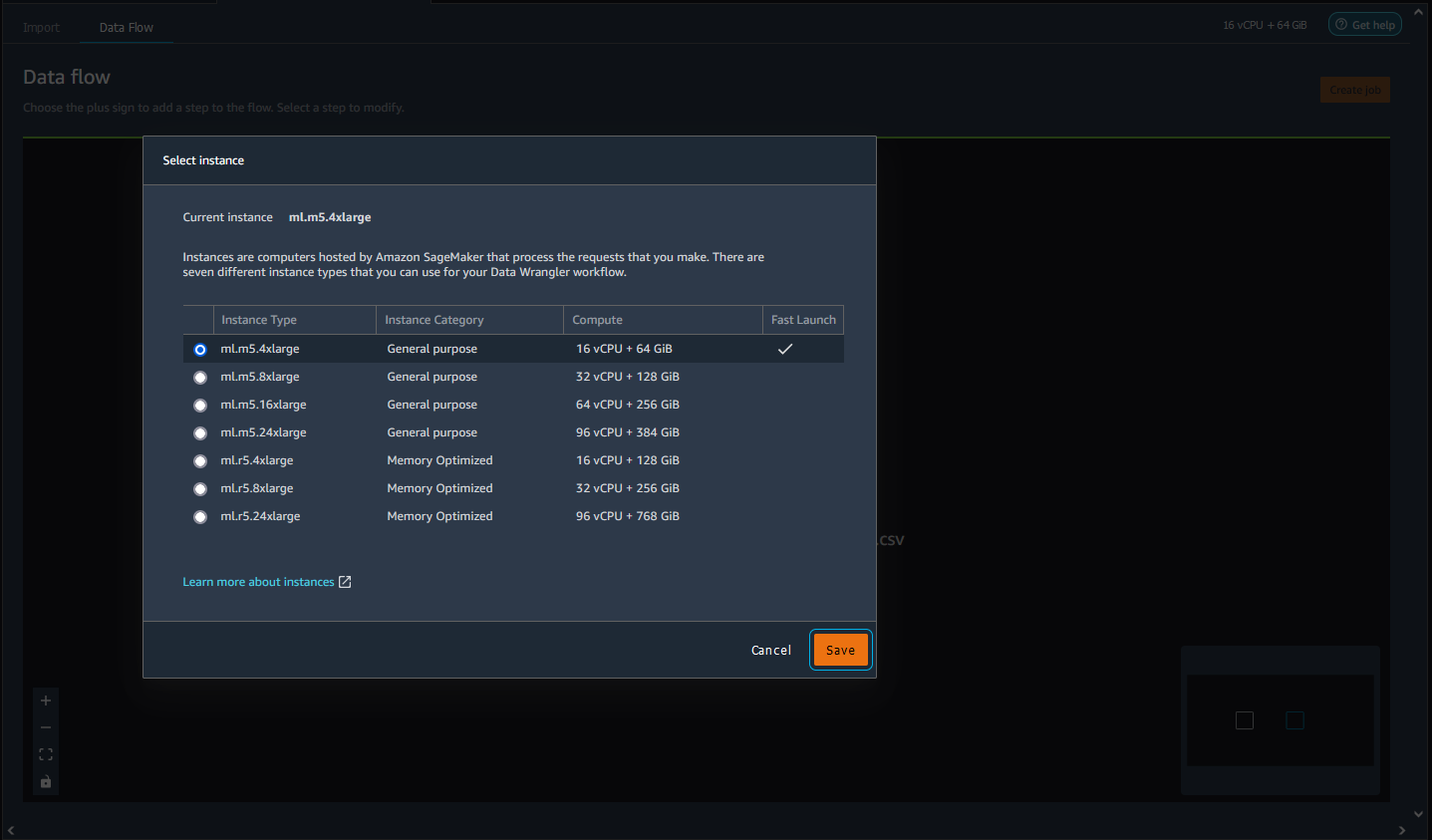
-
选择 Save(保存)。
您需要为所有运行的实例付费。为避免产生额外费用,请关闭您没有手动使用的实例。要关闭正在运行的实例,请使用以下步骤。
关闭运行的实例。
-
选择 UI 左侧的实例图标。下图显示了在哪里选择运行实例图标。
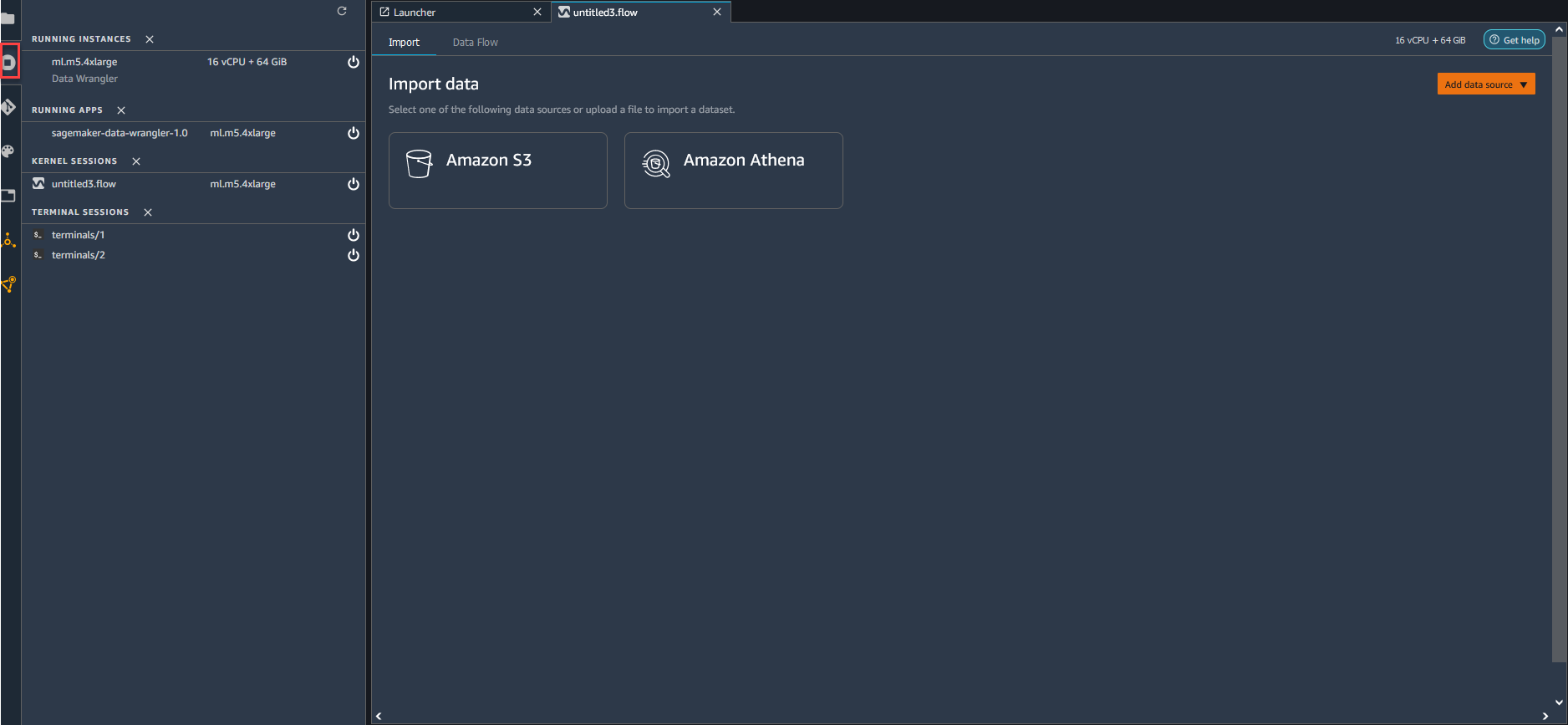
-
选择关闭按钮 (位于要关闭的实例旁边)。
如果您关闭用于运行流程的实例,则无法暂时访问该流程。如果在打开运行之前关闭的实例的流程时出错,请等待大约五分钟,然后再尝试再次打开它。
当您将数据流导出到亚马逊简单存储服务或亚马逊之类的位置 SageMaker 功能商店,Data Wrangler 运营亚马逊 SageMaker 处理作业。您可以使用以下实例之一进行处理作业。有关导出数据的更多信息,请参阅:Export.
| 标准实例 | vCPU | 内存 |
|---|---|---|
| ml.m5.4xlarge | 16 | 64 GiB |
| ml.m5.12xlarge | 48 |
192 GiB |
| ml.m5.24xlarge | 96 | 384 GiB |
有关使用可用实例类型的每小时成本的更多信息,请参阅SageMaker 定价
数据流 UI
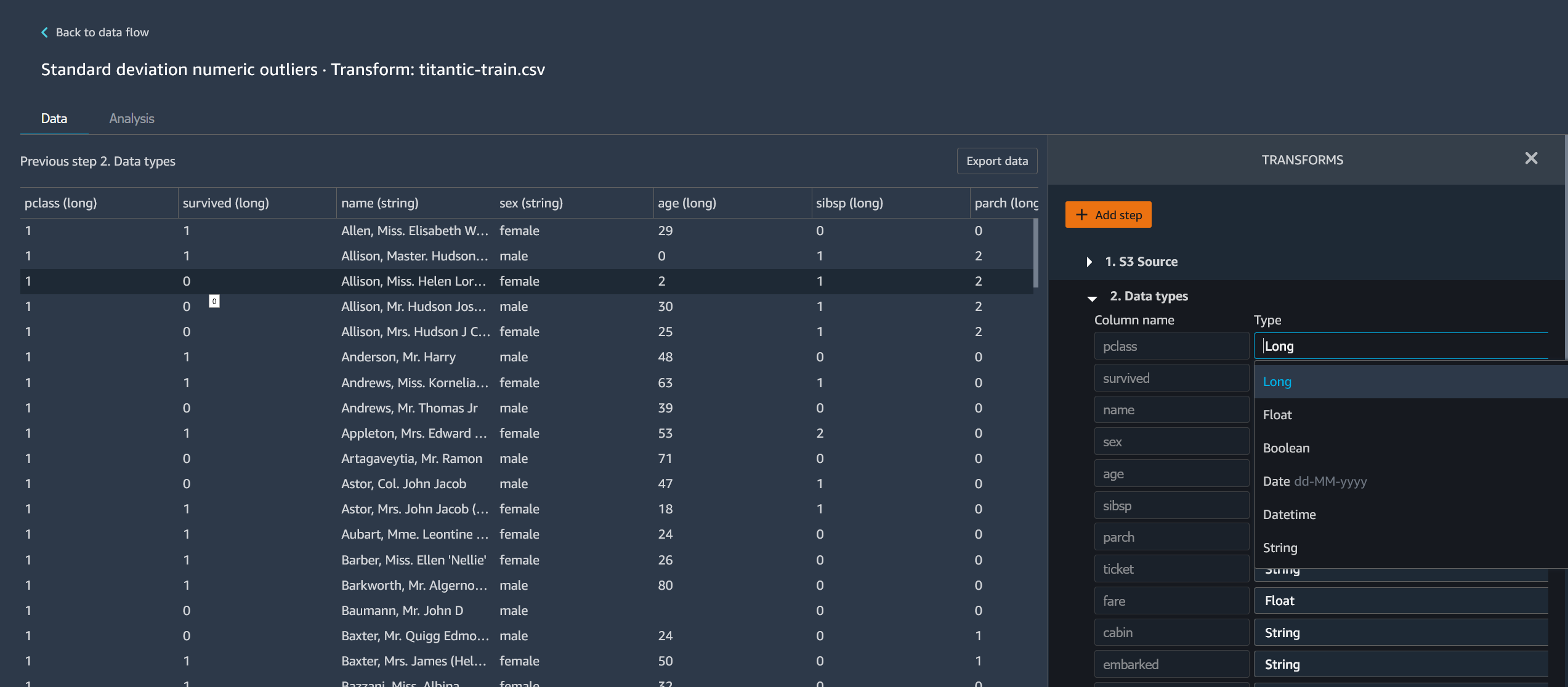
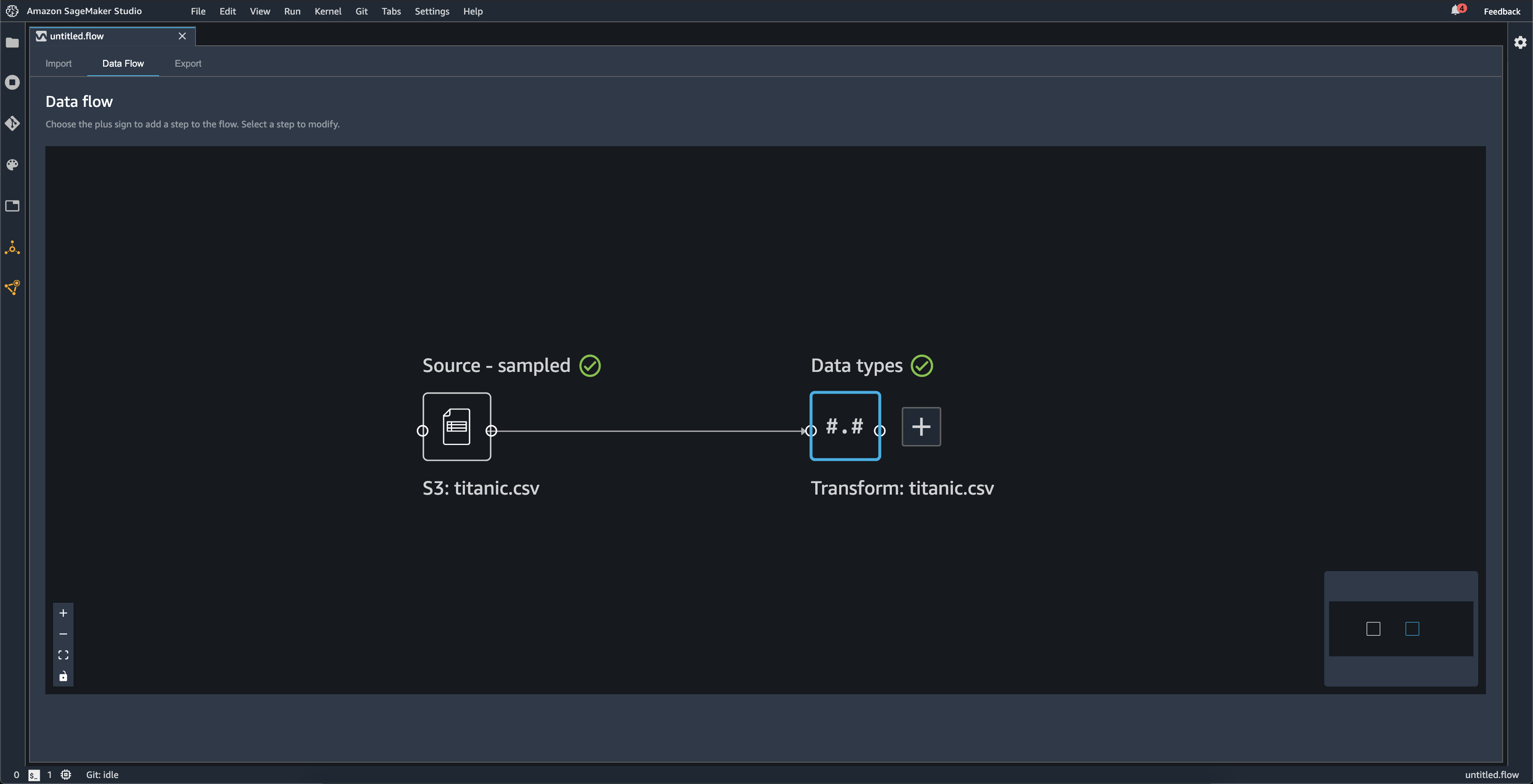
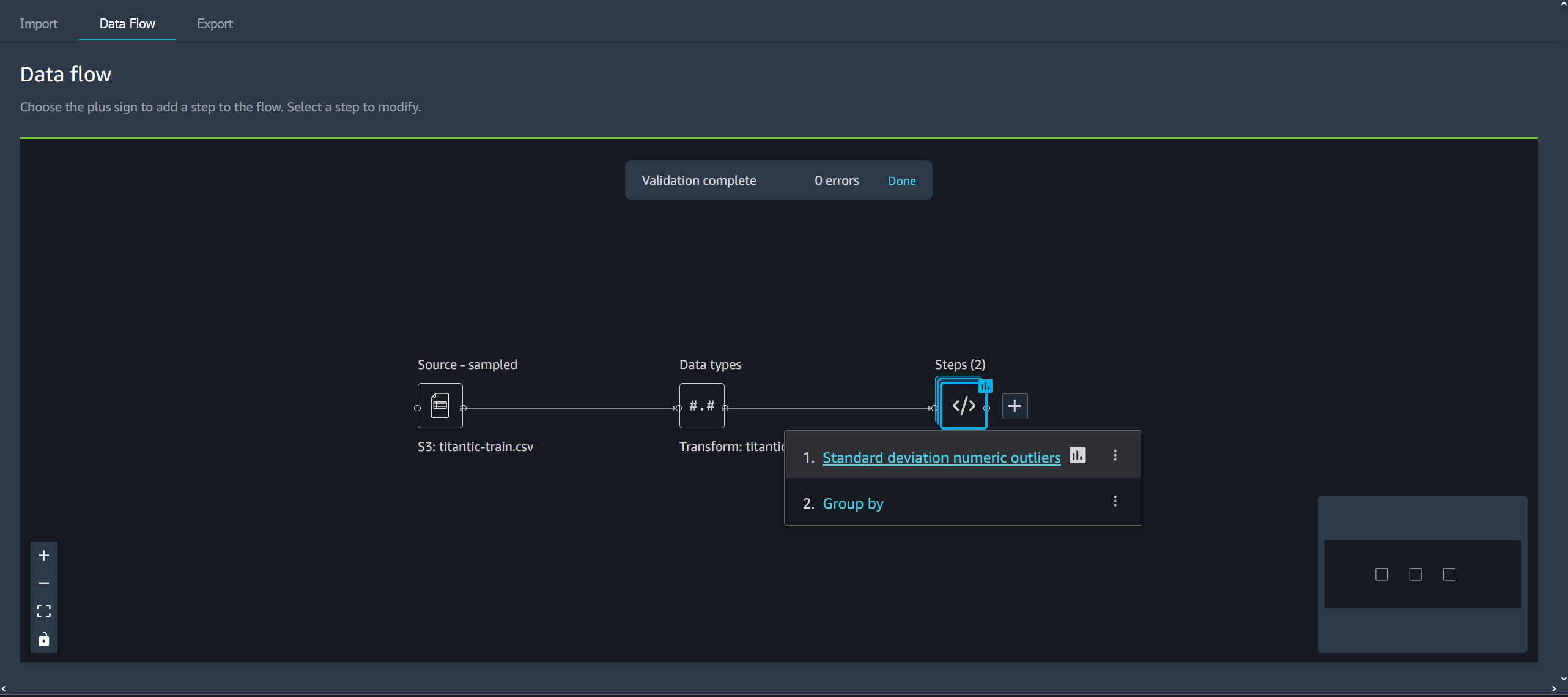
导入数据集时,原始数据集将显示在数据流中并命名为源. 如果您在导入数据时启用了采样,则此数据集将命名为源-采样. Data Wrangler 会自动推断数据集中每列的类型,并创建一个名为数据类型. 您可以选择此框架来更新推断的数据类型。上传单个数据集后,您将看到类似于下图所示的结果:
每次添加转换步骤时,都将创建一个新的数据框。当向同一数据集中添加多个转换步骤(不包括 Join 或 Concatenate)时,它们将堆叠起来。
加入和 Concatenate 创建包含新的已连接或连接数据集的独立步骤。
下图显示了一个数据流,其中包含两个数据集之间的连接以及两个步骤堆栈。第一个堆栈(步骤 (2)) 向中推断的类型添加了两个转换数据类型数据集。这些区域有:下游堆栈或右侧的堆栈,将名为的连接所产生的转换添加到数据集演示加入.
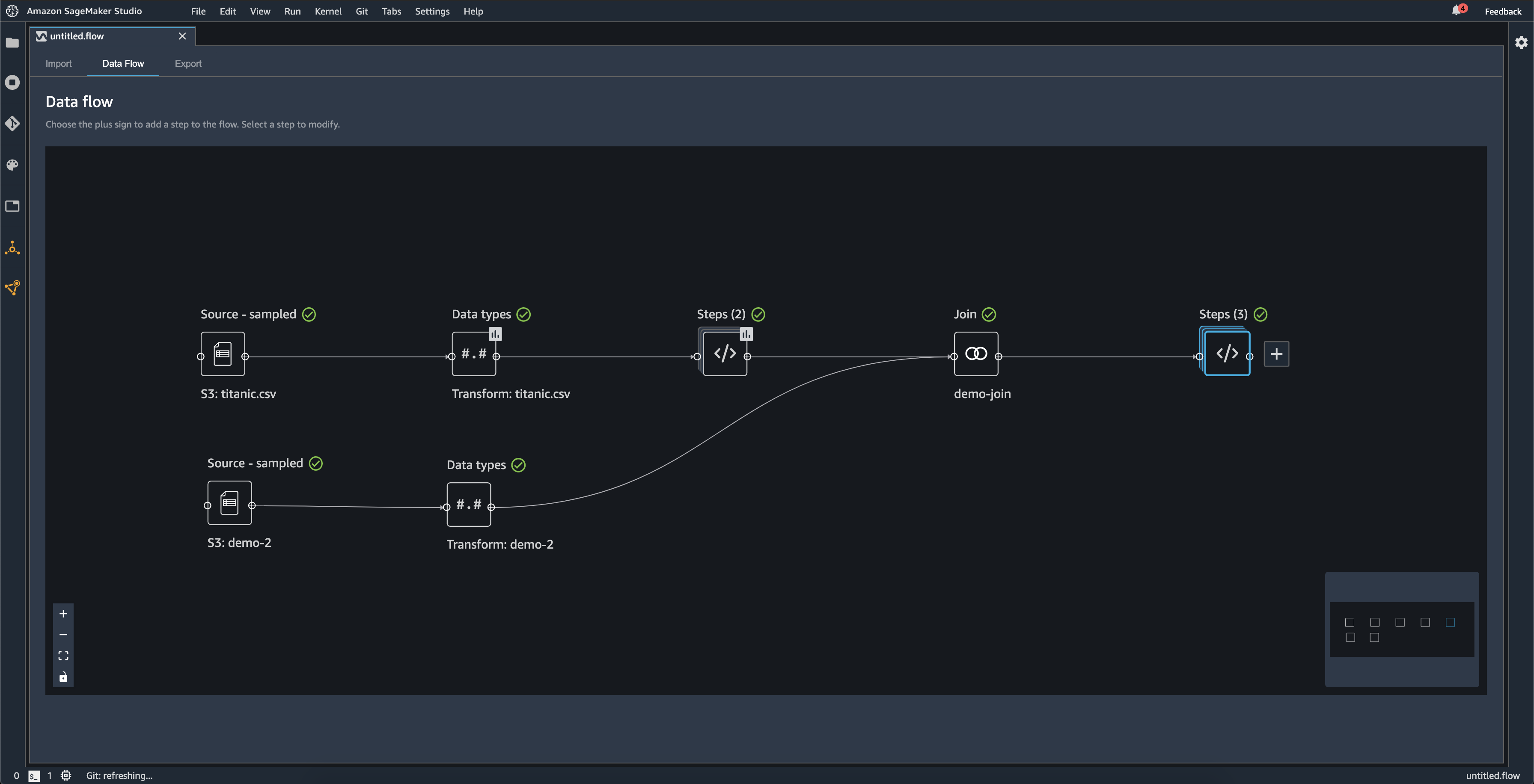
数据流右下角的小灰色框提供了流程中堆栈和步骤的数量以及流程布局的概述。灰色框内的较亮框表示 UI 视图中的步骤。您可以使用此框查看数据流中不属于 UI 视图的部分。使用适合屏幕图标 (
 ) 将所有步骤和数据集填充到 UI 视图中。
) 将所有步骤和数据集填充到 UI 视图中。
左下角的导航栏包含可用于放大的图标 (
 )和输出(
)和输出(
 ),然后调整数据流的大小以适应屏幕(
)。使用锁图标 (
),然后调整数据流的大小以适应屏幕(
)。使用锁图标 (
 ) 来锁定和解锁屏幕上每个步骤的位置。
) 来锁定和解锁屏幕上每个步骤的位置。
向数据流添加一个步骤
Select+选择任何数据集或之前添加的步骤旁边,然后选择以下选项之一:
-
编辑数据类型(对于数据类型仅限步骤):如果您还没有将任何转换添加到数据类型步骤,你可以选择编辑数据类型以更新导入数据集时 Data Wrangler 推断的数据类型。
-
添加转换:添加新的转换步骤。请参阅转换数据以了解有关可以添加的数据转换的更多信息。
-
添加分析:添加分析。您可以使用此选项在数据流中的任何时候分析数据。将一个或多个分析添加到步骤时,一个分析图标 (
 ) 出现在该步骤中。请参阅可视化以了解有关可以添加的分析的更多信息。
) 出现在该步骤中。请参阅可视化以了解有关可以添加的分析的更多信息。 -
加入:连接两个数据集并将生成的数据集添加到数据流中。要了解更多信息,请参阅 加入数据集。
-
连接:连接两个数据集并将生成的数据集添加到数据流中。要了解更多信息,请参阅 连接数据集。
从数据流中删除步骤
要删除步骤,请选择该步骤并选择Delete. 如果节点是具有单个输入的节点,则只删除所选步骤。删除具有单个输入的步骤并不会删除该步骤之后的步骤。如果要删除源、加入或连接节点的步骤,则它之后的所有步骤也将被删除。
要从步骤堆栈中删除步骤,请选择堆栈,然后选择要删除的步骤。
您可以使用以下过程之一删除步骤,而不删除下游步骤。
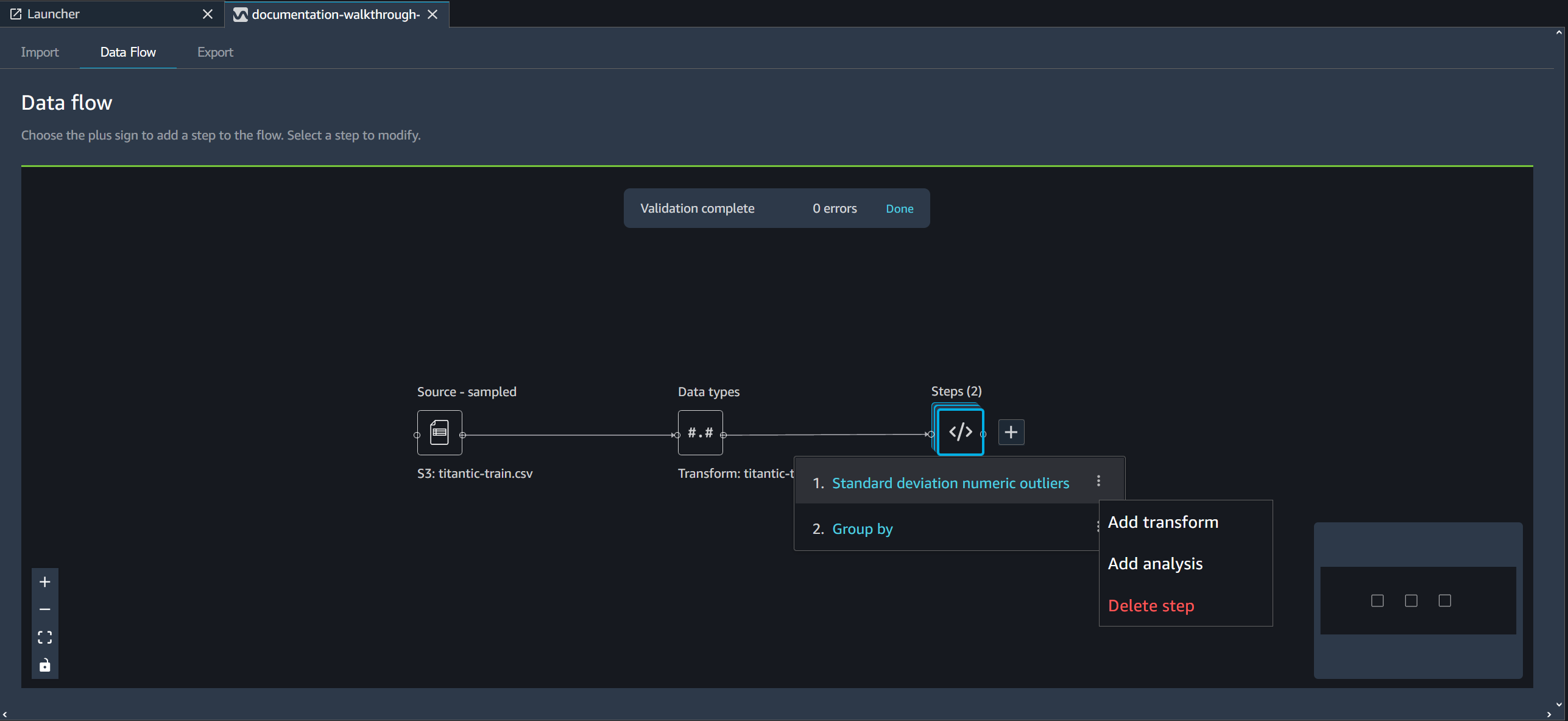
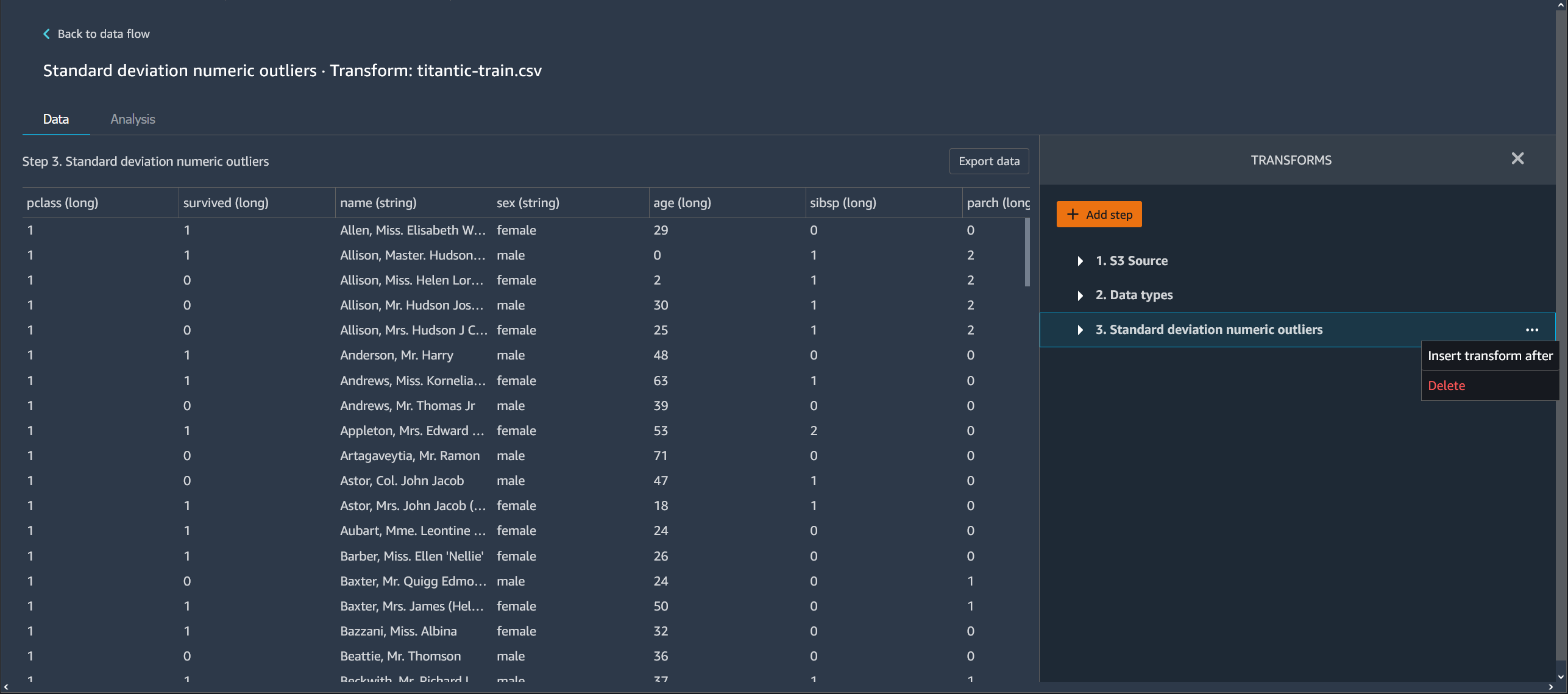
编辑数据 Wrangler 流程中的步骤
您可以编辑在 Data Wrangler 流程中添加的每个步骤。通过编辑步骤,您可以更改列的转换或数据类型。您可以编辑步骤以进行更改,从而使您能够执行更好的分析。
你可以通过多种方法来编辑步骤。一些例子包括更改估算法或更改将值视为异常值的阈值。
可以使用以下过程编辑步骤。
要编辑步骤,请执行以下操作。
-
在 Data Wrangler 流程中选择一个步骤以打开表格视图。
-
在数据流中选择一个步骤。
-
编辑该步骤。
以下是编辑步骤的示例。