本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
Autopilot 模型洞察
亚马逊 SageMaker 模型监视器报告提供了 AutoML 作业在自动驾驶仪实验排行榜中生成的候选模型的见解和质量信息。该报告仅为最佳分类模型候选人提供模型见解图表。这包括了解误报/假负面,真正的阳性和误报之间的权衡,以及精度与召回之间的权衡。
Autopilot 还为用于衡量其预测质量的所有候选模型提供标量指标。默认情况下,排行榜视图包括这些指标。为候选模型自动计算的指标取决于要解决的问题的类型。
-
回归:MSE
-
二进制分类:准确性,F1,AUC
-
多类别分类:准确性,f1宏
您可以使用相关指标对候选模型进行排序,以帮助您选择和部署满足业务需求的模型。有关这些指标的定义,请参阅Autopilot 候选项指标主题。
这些区域有: SageMaker 模型监视器报告包含描述 Autopilot 作业特征的详细信息、指标表和几个模型见解。其中包括与分类问题类型相关的模型图表。您可以在中访问这些报告 SageMaker 来自工作室性能打开的页面上的选项卡以确认 AutoML 作业已完成。有关如何创建和运行 AutoML 作业的说明 SageMaker 工作室,请参阅创建亚马逊 SageMaker Autopilot 实验.
模型详细信息和指标表
模型详细信息包括以下信息。
-
Autopilot 候选项
-
Autopilot Job 名称
-
问题类型
-
目标指标
-
优化方向
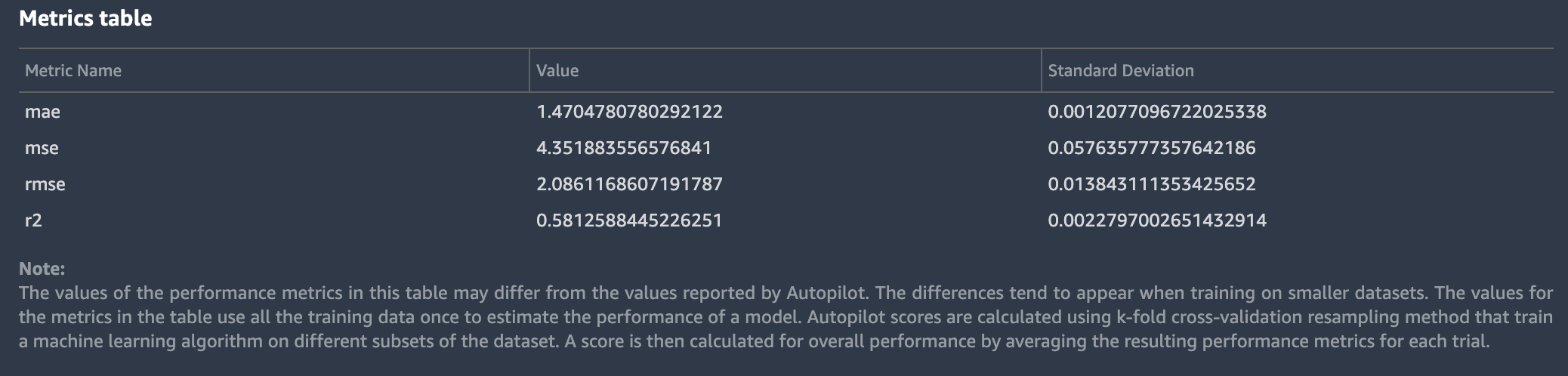
模型质量信息是由预先构建的 SageMaker 模型监控器容器。生成的报告的内容取决于解决的问题类型:回归、二进制分类或多类分类。该报告指定了评估数据集中包含的行数以及评估的发生时间。
以下是 AutoML 作业为回归问题生成的模型监视器报告中的指标表示例。
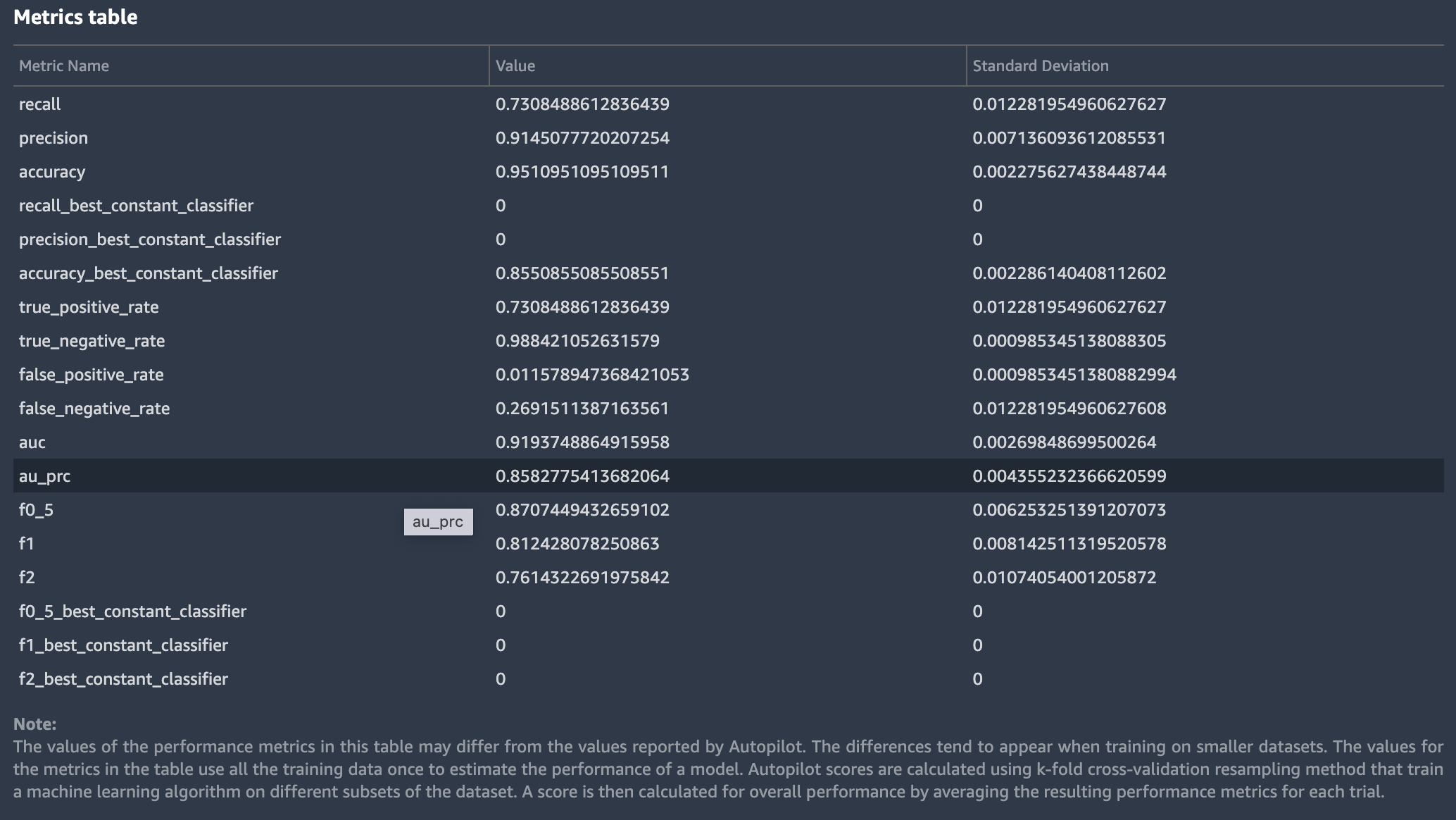
以下是 AutoML 作业为二进制分类问题生成的模型监视器报告中的指标表示例。
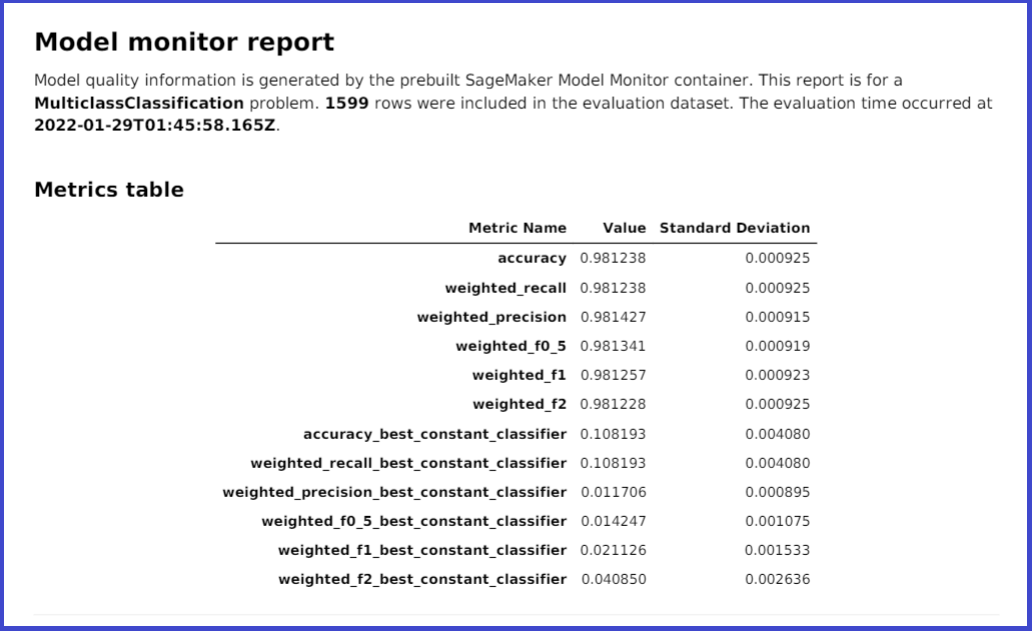
以下是 AutoML 作业为多类分类问题生成的模型监视器报告中的指标表示例。
混乱矩阵
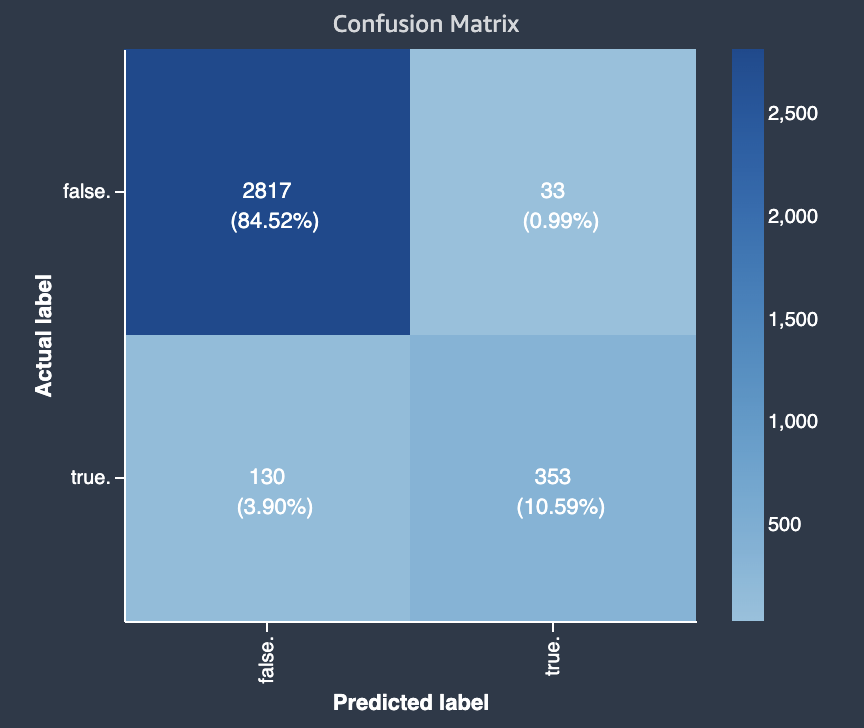
混淆矩阵提供一种可视化为不同类别进行二元和多类别分类预测的准确性的方法。混淆矩阵是一个表,其中包含实际标签的正确和不正确预测的百分比。混淆矩阵中的每一行都表示如何按模型预测的标签对实际标签进行分类。准确预测的百分比在对角线上,从左上角到右下角。非对角线百分比表示模型预测的错误分类类型。这些错误的预测就是混淆值。
以下是一个二元分类问题的混淆矩阵示例。
此为多类别分类问题的混淆矩阵示例。
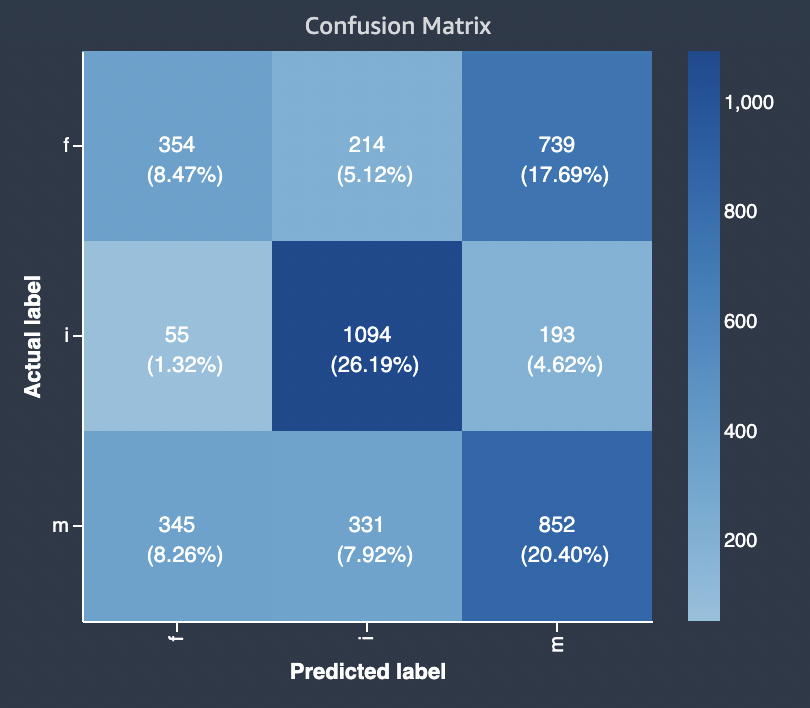
此报告提供了一个混淆矩阵,最多可容纳 15 个多类分类问题类型的标签。标签按顺序列出,从预测最不准确的标签到预测最准确的标签。如果行显示Nan,这意味着验证数据集没有该标签的行。
接收器操作特征曲线下的面积
接收机操作特征曲线下的区域(AUC ROC 曲线)表示真正阳性和误报率之间的权衡。AUC ROC 曲线是用于二进制分类模型的行业标准准确度指标。AUC 衡量模型为正面示例预测出相比负面示例更高分数的能力。AUC 指标提供了对所有可能分类阈值中模型性能的综合度量。
AUC 指标返回从零 (0) 到一 (1) 的十进制值。接近 1 的 AUC 值指示高度准确的 ML 模型。接近 0.5 的值指示 ML 模型比随便猜测好不了多少。值接近 0 的情况很少见,这些值通常表示数据有问题。基本上,接近 0 的 AUC 表示 ML 模型已学习了正确的模式,但使用它们来预测尽可能不准确。例如,0 预测为 1,1 为 0。有关 AUC 指标的更多信息,请参阅接收器运行特点
分类的二进制模型 no-better-than-random 猜测,真实和误报率相等,AUC 分数为 0.5。表示随机二进制分类器的曲线是接收器运行特征图中的对角线虚线红线。更准确的分类模型的曲线高于这个随机基线,其中真正阳性的比率超过了误报率。
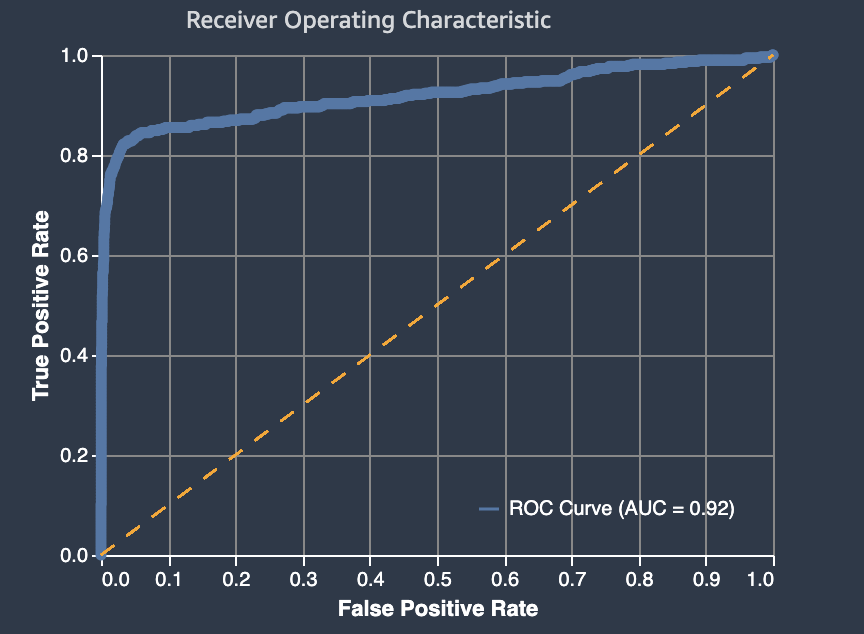
这些区域有:误报率(FPR) 衡量错误警报率或虚假预测为正例的实际负例的比率。范围为 0 至 1。较小的值表示更好的预测准确度。
-
对于 = FP/ (FP+TN)
这些区域有:真正汇率(TPR)衡量预测为阳性的实际阳性分数。范围为 0 至 1。较大的值(1 为最大)表示更好的预测准确度。
-
TPR = TP/ (TP+FN)
这些费率的定义如下。
-
正确预测
-
真正向(TP): 预测的值为 1,真正的值为 1。
-
真正负值(TN): 预测的值为 0,真正的值为 0。
-
-
错误预测
-
误报(FP): 预测的值为 1,但真正的值为 0。
-
误报(FN): 预测的值为 0,但真正的值为 1。
-
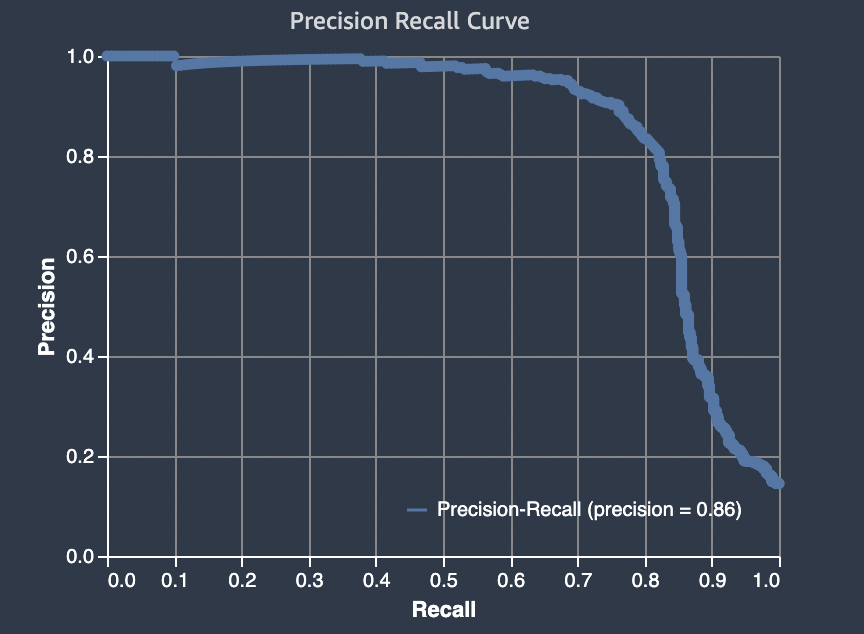
精确召回曲线
精度召回曲线代表了在二进制分类问题中使用的不同阈值的精度和召回之间的权衡。二进制分类问题的目的是尽可能多地对训练数据集中标记为正面的相关元素进行正确分类。召回率高但精度低的系统会返回大量相关结果,但与训练标签相比,其预测标签中有很高百分比的标签是不正确的。高精度但召回率低的系统返回的相关结果较少,但与训练标签相比,很高百分比的预测标签是正确的。具有高精度和高召回能力的完美系统可产生许多正确标记的结果。有关更多信息,请参阅 。精度和召回
精度精度衡量预测为正向的实际正例的比率。范围为 0 至 1。较大的值表示预测的值准确度越高。
-
精度 = TP/(TP+FP)
调用精度衡量实际正例与样本中预测为正向的实际正例的比率。这也称为敏感度和真正的正率。范围为 0 至 1。值越大表示从样本中检测到的正值得更好。
-
召回 = TP/(TP+FN)
亚马逊 SageMaker 自动驾驶仪报告了精确召回曲线 (AUPRC) 下的区域。AUPRC 指标提供了对所有可能分类阈值中模型性能的综合度量。
下面是一个示例,比较了在同一数据集上训练的四种不同模型的精度召回曲线及其 AUPRC 值。