本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
亚马逊 SageMaker Autopilot 数据探索报告
亚马逊 SageMaker Autopilot 会自动清理和预处理您的数据集。高数据质量可实现更高效的机器学习,并生成能够做出更准确预测的模型。如果没有某些领域知识的好处,客户提供的数据集存在的问题,这些问题无法自动修复。例如,回归问题的目标列中的大异常值可能会导致非异常值的预测不佳。根据建模目标,可能需要移除异常值。如果意外地将目标列包括为输入要素之一,则最终模型将验证良好,但对 future 的预测没有什么价值。为了帮助客户发现这些问题,Autopilot 提供了一份数据探索报告,其中包含对数据潜在问题的见解,并建议如何处理这些问题。
为完成管道推荐步骤的每个 Autopilot 作业生成包含报告的数据探索笔记本。该报告存储在 S3 存储桶中,可以从输出路径中访问。数据探索报告的路径通常遵循以下模式:
[s3 output path]/[name of the automl job]/sagemaker-automl-candidates/[name of processing job used for data analysis]/notebooks/SageMakerAutopilotDataExplorationNotebook.ipynb
数据探索笔记本的位置可以从 Autopilot API 中使用DescribeAutoMLJob操作响应,存储在数据探索笔记本电脑位置.
从运行自动驾驶仪时 SageMaker Studio,您可以打开描述 Autopilot 作业的 UI,然后选择开放数据探索笔记本来自自动驾驶仪职位描述页面。
数据探索报告是在训练过程开始之前根据您的数据生成的。这样,您就可以停止可能导致结果不佳或毫无意义的 AutoPilot 作业,并在重新运行 Autopilot 之前解决数据集的任何问题或改进。这使您有机会利用自己的领域专业知识来手动提高数据质量,然后再在精心策划的数据集上训练模型。
生成的数据报告只包含静态降价,可以在任何 Jupyter 环境中打开。包含报告的笔记本可以转换为其他格式,例如 PDF 或 HTML。有关转化的更多信息,请参阅使用 nbconvert 脚本将 Jupyter 笔记本转换为其他格式。
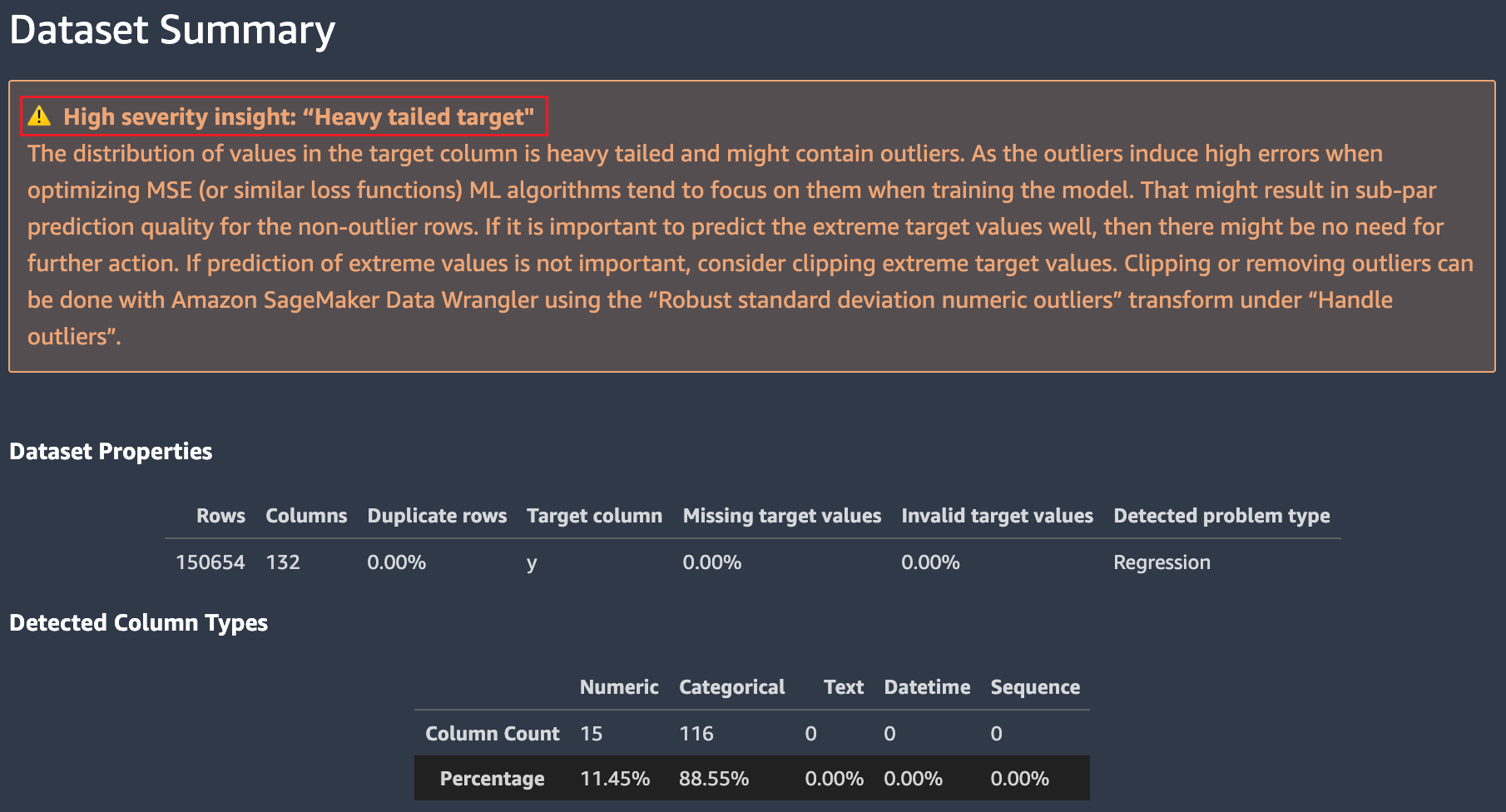
数据集摘要
该数据集摘要提供了表征数据集的关键统计数据。它旨在在您的数据集出现亚马逊问题时向您提供快速警报 SageMaker 自动驾驶仪已检测到,这可能需要你的干预。这些见解显示为被归类为 “高” 或 “低” 严重性的警告。分类取决于对该问题将对模型性能产生不利影响的信心程度。
严重性高和低严重性见解以弹出窗口的形式出现在摘要中。对于大多数见解,我们提供了有关如何确认数据集存在需要注意的问题的建议。还提供了关于如何解决问题的建议。
Autopilot 提供了有关我们数据集中缺失或无效目标值的其他统计信息,以帮助您检测可能无法通过高严重性洞察捕获的其他问题。特定类型的列数意外可能表明数据集中可能缺少某些要使用的列。它还可能表明数据的准备或存储方式存在问题。修复 Autopilot 引起你注意的这些数据问题可以提高针对数据训练的机器学习模型的性能。
报告的摘要部分和其他相关章节中显示了严重性高的见解。通常根据数据报告的部分给出高度和低严重性见解的示例。
目标分析
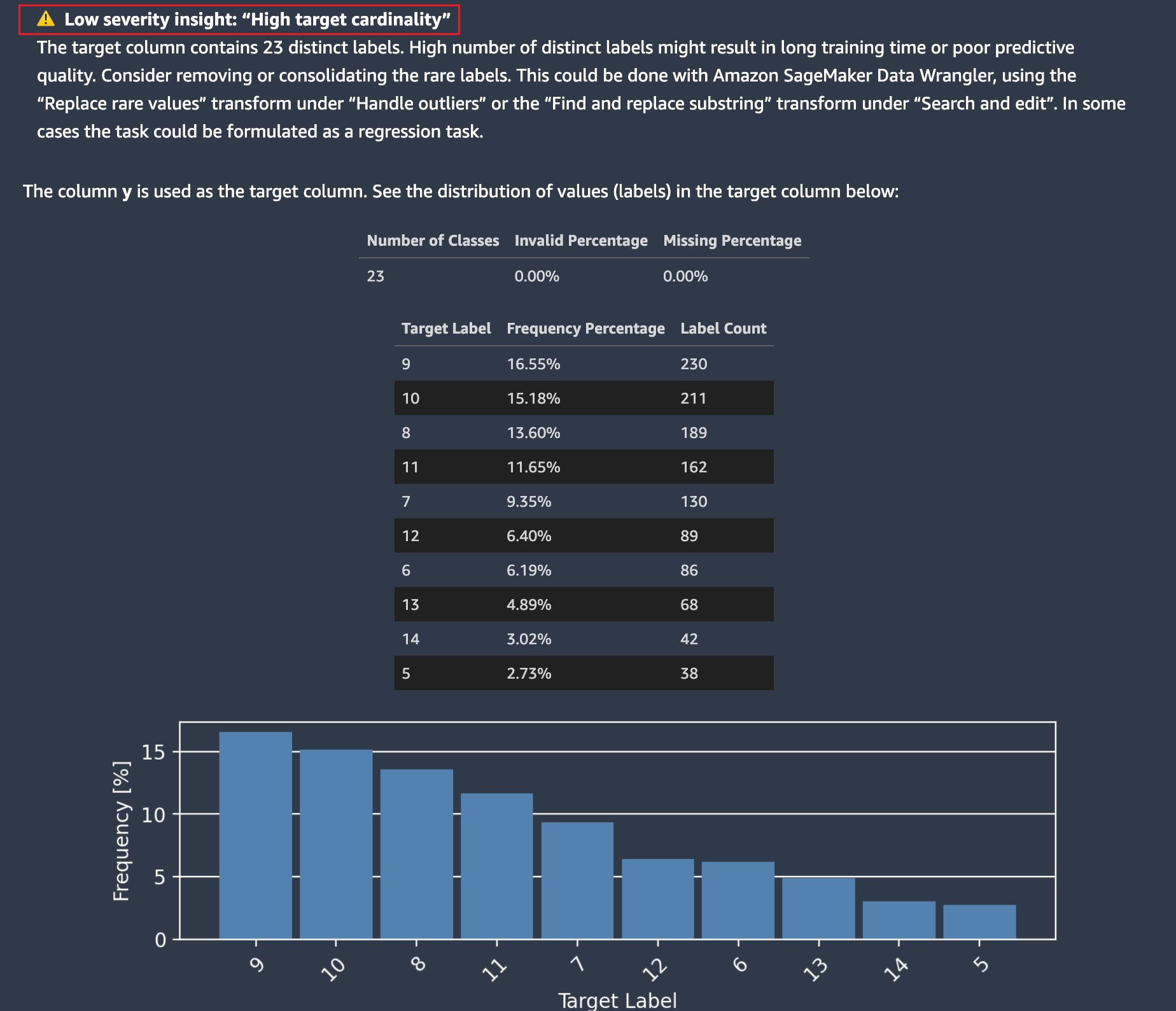
本节显示了与目标列中值分布相关的各种高严重性和低严重性见解。你应该检查目标列是否包含正确的值。目标列中的值不正确可能会导致机器学习模型不符合预期业务目的。本节介绍了严重性高和低严重性的几个数据见解。下面是几个示例。
-
异常值目标值-偏斜或不寻常的回归目标分布,例如重尾目标。
-
高或低目标基数-不常见的类别标签数量或大量的唯一分类进行分类。
对于回归和分类问题类型,没有有效值,例如数字无穷大,NaN或者目标列中的空白空间浮出水面。根据问题类型,会显示不同的数据集统计信息。回归问题的目标列值分布允许您验证分布是否符合预期值。
以下示例显示了有关目标列值分布的 Autopilot 数据报告。
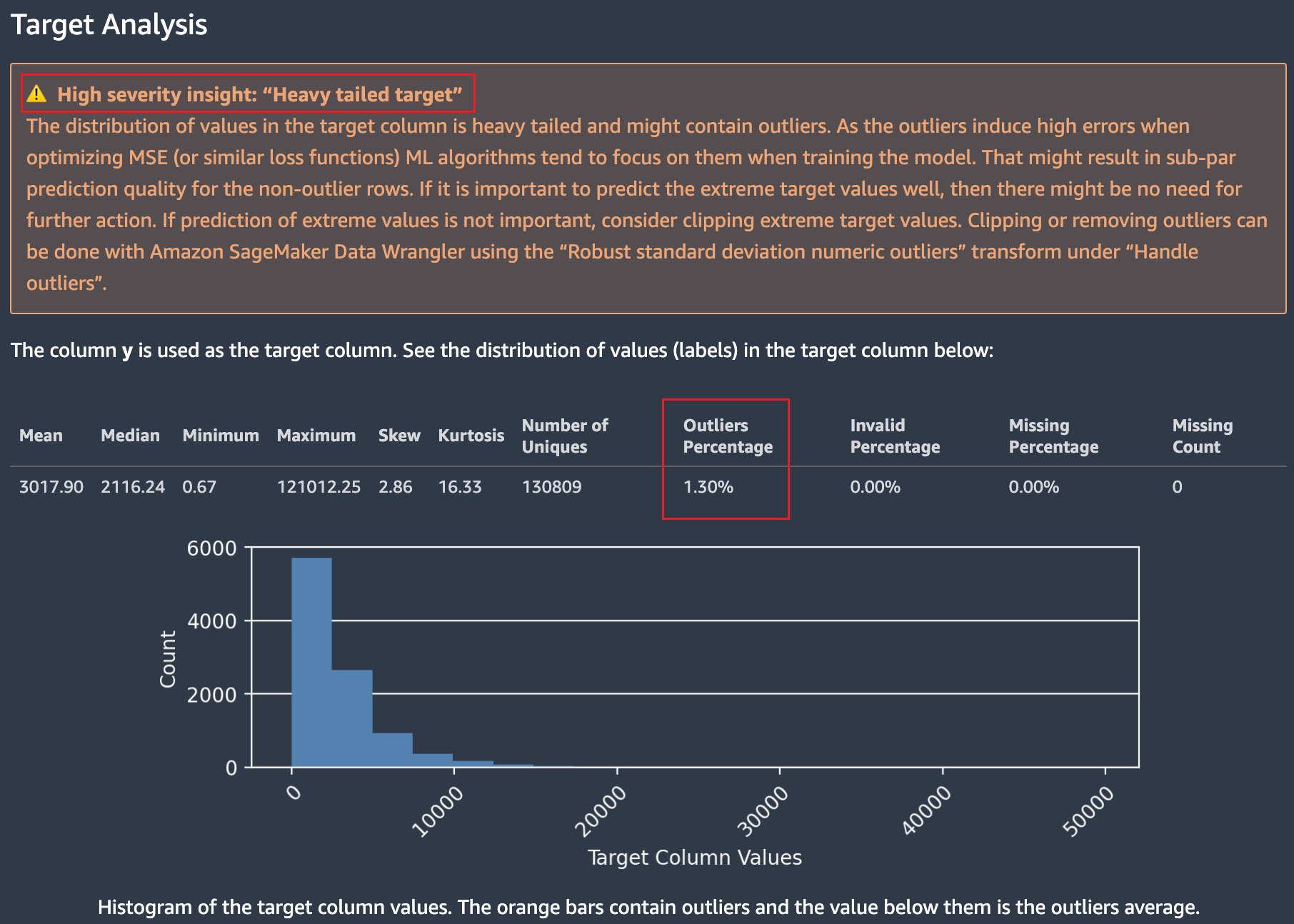
显示了有关目标值及其分布的多个统计数据。如果任何异常值、无效值或缺失百分比大于零,则会显示这些值,以便您可以调查数据包含不可用的目标值的原因。一些不可用的目标值被突出显示为严重性较低的洞察警告。在以下示例中,`符号被意外添加到目标列中,这使得无法解析目标的数字值。

为了帮助您识别有问题的值和一些受影响的行,Autopilot 提供了包含不可用或异常目标值的行的示例。将用于分类的标签分布制表和绘制,以便您也可以对其进行分析。
您可以在中找到本节和其他章节中介绍的所有术语的定义定义报告笔记本底部的部分。
数据示例
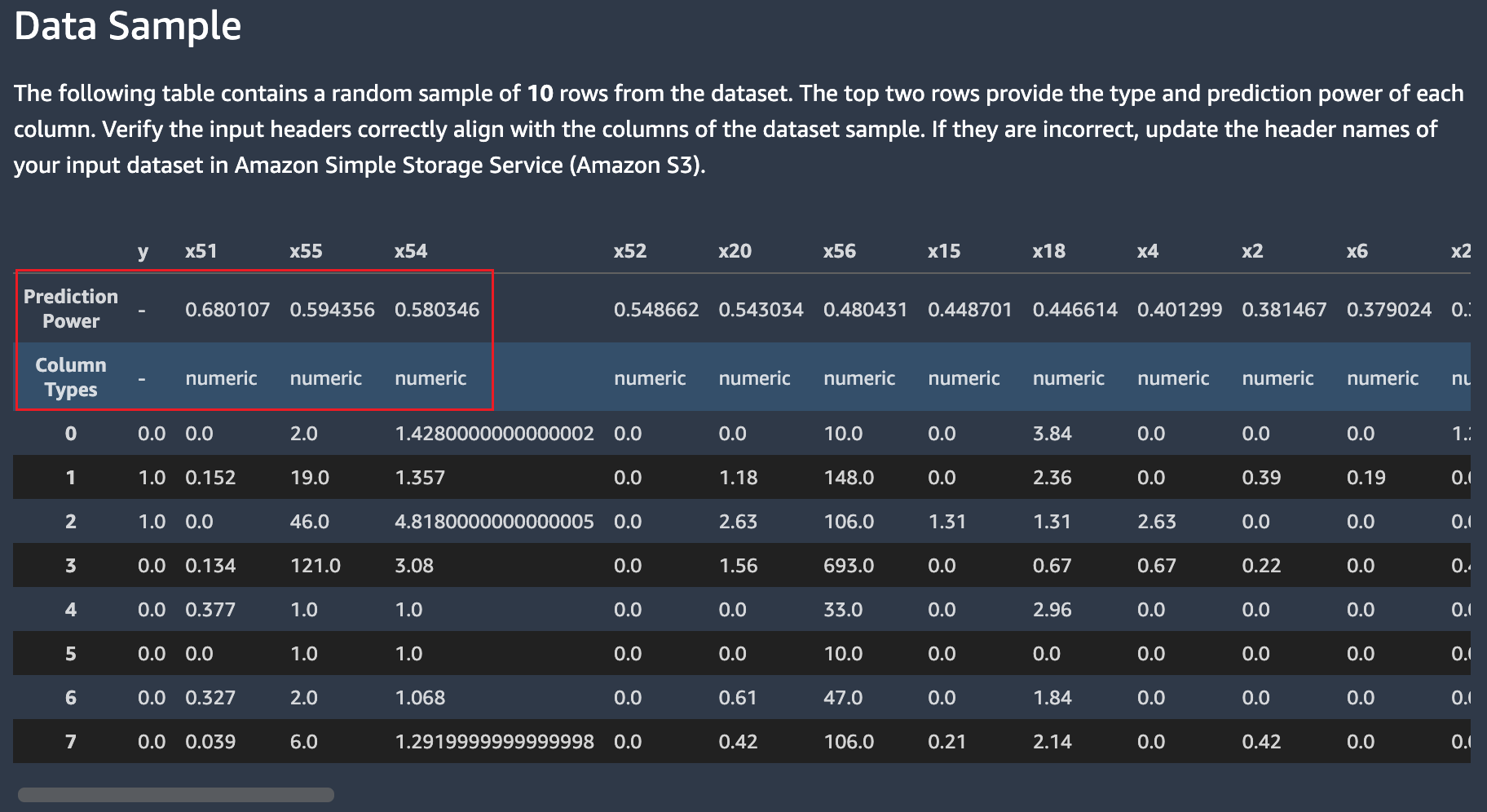
为了进一步帮助您发现数据集的问题,亚马逊会提供实际数据样本供您检查 SageMaker Autopilot. 样本表水平滚动。它可用于验证所使用的数据集中是否存在所有必要的列。如果缺少数据列,则在导入需要调查的数据集之前可能会出现预处理问题。
亚马逊计算预测能力的度量 SageMaker Autopilot 可用于识别伪装为输入列的目标列。它有助于将注意力集中在可能很重要的专栏上,因为它们具有较高的预测能力。有关预测功率的更多信息,请参阅定义部分。
除非您确定预测能力是适合自己的使用案例的合适度量,否则建议您不要使用预测能力来替代功能重要性。
重复的行
如果数据集中存在重复行,则亚马逊 SageMaker 自动驾驶仪会显示其中的一个样本。
不建议在将数据集提供给 Autopilot 之前通过向上取样来平衡数据集。这可能会导致 Autopilot 训练的模型的验证分数不准确,并且生成的模型可能无法使用。
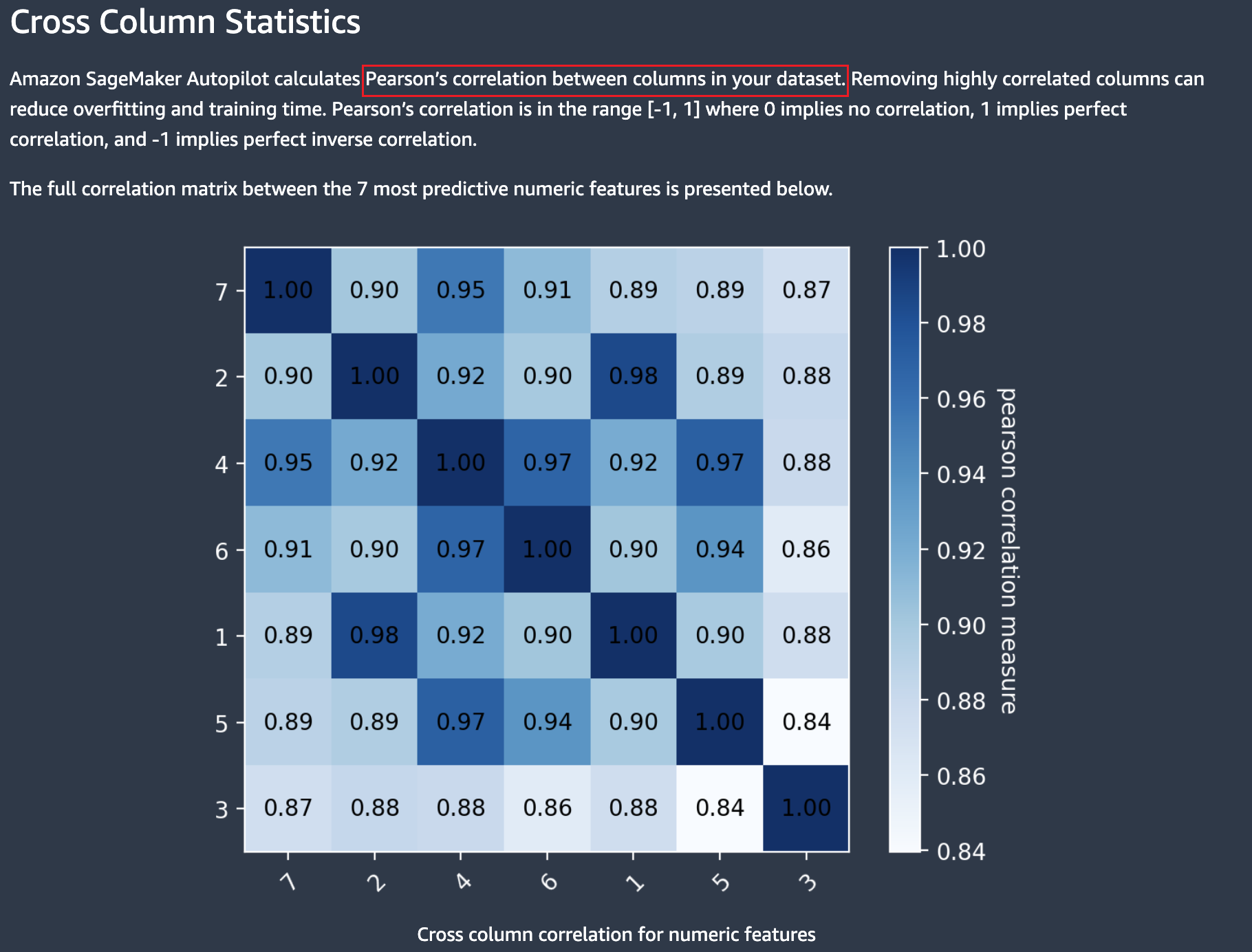
跨栏相关性
还使用标准的互相关矩阵图表显示数字列相关性。您可以使用它来减少数据集中的要素数量。较少的功能减少了模型过度拟合的可能性,并可以通过两种方式降低生产成本。它减少了所需的 Autopilot 运行时间,对于某些应用程序而言,可以使数据收集过程更便宜。
接近 +1 的值和接近 -1 的值表示两个要素分别是正面和负面的两个要素高度相关性。
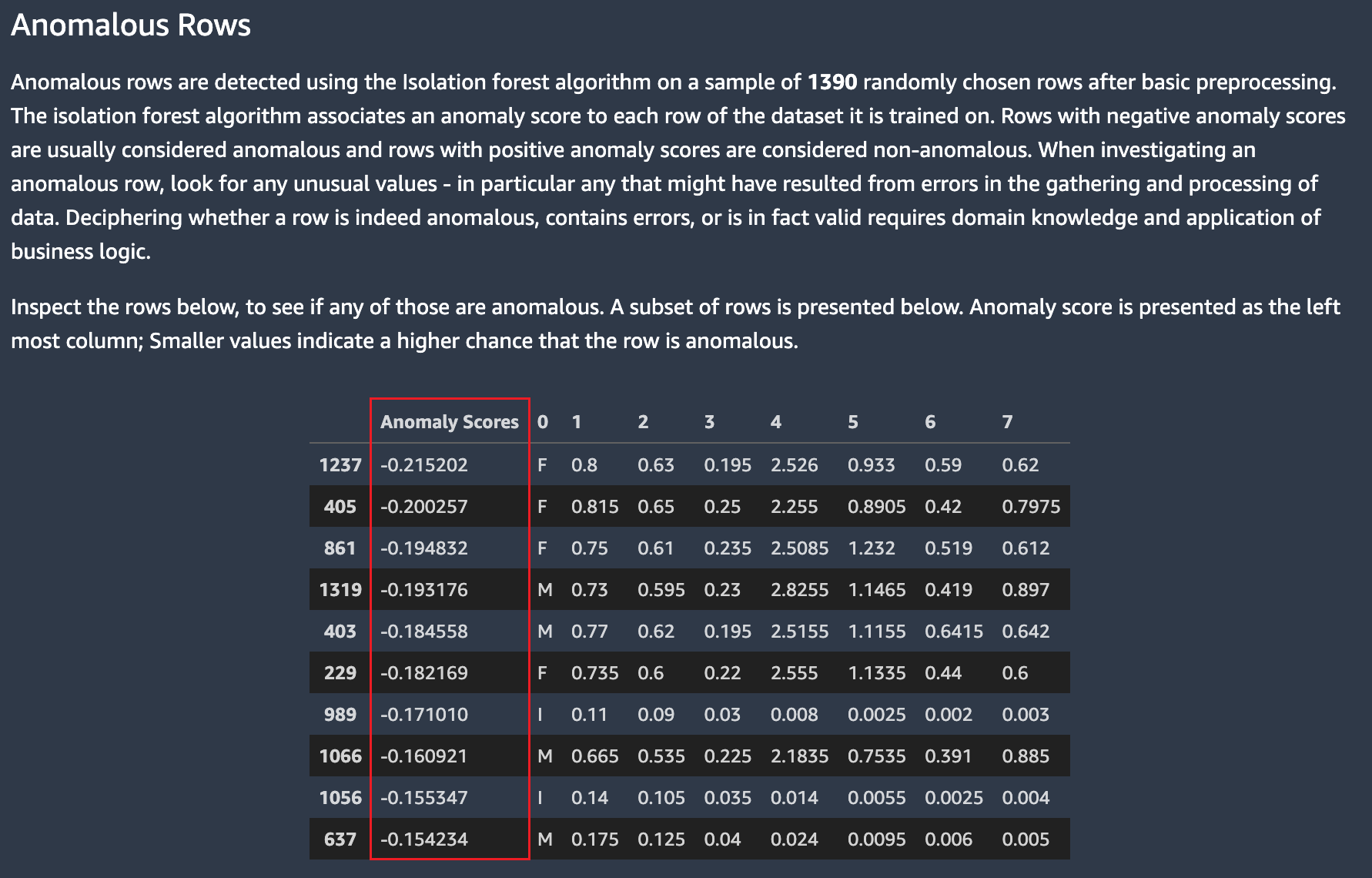
异常行
亚马逊 SageMaker Autopilot 可以检测数据集中的哪些行可能是异常的。然后,它会为每行分配一个异常分数。具有负异常分数的行被认为是异常的。
缺少值、基数和描述性统计
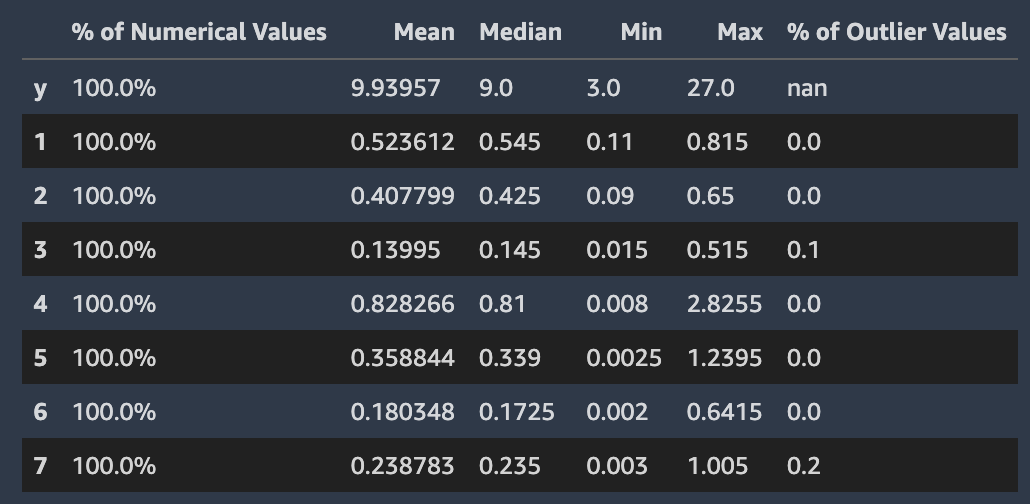
亚马逊 SageMaker Autopilot 检查并报告数据集各列的属性。在提供此分析的数据报告的每个部分中,内容都按顺序排列,以便您可以首先检查最 “可疑” 的值。使用这些统计数据,您可以改进单个列的内容,并提高 Autopilot 生成的模型的质量。
Autopilot 计算包含它们的列中的分类值的几个统计数据。其中包括唯一条目的数量以及对于文本而言,唯一单词的数量。这些都在表格中显示,供您检查。
Autopilot 计算包含这些数值的列中的数值的几个标准统计数据。其中包括平均值、中值、最小值和最大值,以及数值类型和异常值的百分比。这些都在表格中显示,供您检查。