使用查询编辑器 v2
查询编辑器 v2 主要用于编辑和运行查询、可视化结果以及与团队共享您的工作。使用查询编辑器 v2,您可以创建数据库、架构、表和用户定义的函数(UDF)。在树视图面板中,对于每个数据库,您都可以查看其架构。对于每个架构,您都可以查看其表、视图、UDF 和存储过程。
主题
打开查询编辑器 v2
如要打开查询编辑器 v2
登录 Amazon Web Services Management Console,然后通过以下网址打开 Amazon Redshift 控制台:https://console.aws.amazon.com/redshift/
。 在导航器菜单中,选择 Editor(编辑器),然后选择 Query editor V2(查询编辑器 V2)。此时将在新的浏览器标签页中打开查询编辑器 v2。
查询编辑器页面有一个导航器菜单,您可以在其中选择视图,如下所示:
- 数据库

您可以管理和查询以表形式组织并包含在数据库中的数据。数据库可以包含存储的数据,也可以包含对存储在其他位置(如 Amazon S3)的数据的引用。连接到包含在集群或无服务器工作组中的数据库。
在 Database(数据库)视图中工作时,您有以下控件:
Cluster(集群)或 Workgroup(工作组)字段显示您当前连接到的集群或工作组的名称。Database(数据库)字段显示集群或工作组内的数据库。您在 Database(数据库)视图原定设置中执行的操作会对您选择的数据库执行操作。
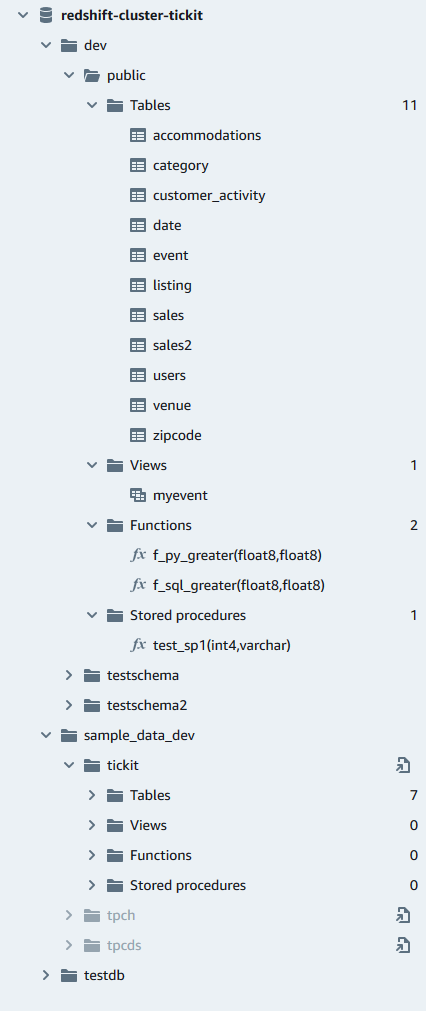
集群或工作组、数据库和架构的树视图层次结构视图。在架构下,您可以使用表、视图、函数和存储过程。树视图中的每个对象都支持上下文菜单来执行相关操作,例如对对象进行 Refresh(刷新)或 Drop(删除)。
通过
 Create(创建)操作来创建数据库、架构、表和函数。
Create(创建)操作来创建数据库、架构、表和函数。通过
 Load data(加载数据)操作将数据从 Simple Storage Service(Amazon S3)加载到数据库。
Load data(加载数据)操作将数据从 Simple Storage Service(Amazon S3)加载到数据库。通过
 Save(保存)图标来保存您的查询。
Save(保存)图标来保存您的查询。通过
 Shortcuts(快捷方式)图标来显示编辑器的键盘快捷键。
Shortcuts(快捷方式)图标来显示编辑器的键盘快捷键。可以在
Editor(编辑器)区域中输入和运行查询。运行查询后,Result(结果)选项卡随即显示结果。您可以打开此处的 Chart(图表)来可视化您的结果。还可以 Export(导出)结果。
- Notebook(笔记本)区域,您可以在其中添加各部分,以输入和运行 SQL 或添加 Markdown。
运行查询后,Result(结果)选项卡随即显示结果。您可以在此处 Export(导出)结果。
- 查询

查询包含用于管理和查询数据库中数据的 SQL 命令。当您使用查询编辑器 v2 加载示例数据时,它还会为您创建和保存示例查询。您可以与您的团队共享保存的查询。
- 笔记本

SQL 笔记本包含 SQL 和 Markdown 单元格。使用笔记本可在单个文档中组织、注释及共享多个 SQL 命令。您可以与团队共享笔记本。有关更多信息,请参阅使用 SQL 笔记本(预览版)。。
- 图表

图表是您的数据的可视化表示。查询编辑器 v2 提供了用于创建多种图表并保存它们的工具。您可以与团队共享图表。有关更多信息,请参阅可视化查询结果。
所有查询编辑器 v2 视图都有以下图标:
 Visual mode(可视化模式)图标,可在亮模式和暗模式之间切换。
Visual mode(可视化模式)图标,可在亮模式和暗模式之间切换。 Settings(设置)图标,可显示不同设置屏幕的菜单。
Settings(设置)图标,可显示不同设置屏幕的菜单。 Editor preferences(编辑器首选项)图标,可在使用查询编辑器 v2 时编辑首选项。
Editor preferences(编辑器首选项)图标,可在使用查询编辑器 v2 时编辑首选项。 Connections(连接)图标,可查看编辑器选项卡使用的连接。
Connections(连接)图标,可查看编辑器选项卡使用的连接。连接用于检索数据库中的数据。连接是针对特定数据库创建的。使用隔离连接时,在一个编辑器选项卡中更改数据库的 SQL 命令(例如创建临时表)的结果在另一个编辑器选项卡中不可见。在查询编辑器 v2 中打开编辑器选项卡时,原定设置为隔离连接。创建共享连接时,即关闭 Isolated session(隔离会话)开关,同一数据库的其他共享连接的结果对彼此可见。但是,使用数据库的共享连接的各编辑器选项卡不会并行运行。使用相同连接的查询必须等到连接可用。与一个数据库的连接不能与另一个数据库共享,因此 SQL 结果在不同的数据库连接之间不可见。
账户中的任何用户可以激活的连接数由查询编辑器 v2 管理员控制。
 Account settings(账户设置)图标,管理员用于更改账户中所有用户的某些设置。有关更多信息,请参阅更改账户设置。
Account settings(账户设置)图标,管理员用于更改账户中所有用户的某些设置。有关更多信息,请参阅更改账户设置。
连接到 Amazon Redshift 数据库
要连接到数据库,请在树视图面板中选择集群或工作组名称。如果出现提示,请输入连接参数。
当您连接到集群或工作组及其数据库时,需要提供 Database(数据库)名称。您还提供以下身份验证方法之一所需的参数:
- 联合身份用户
-
使用此方法,您的 IAM 角色或 IAM 用户的主体标签必须提供连接详细信息。您可以在 Amazon Identity and Access Management 或您的身份提供者 (IdP) 中配置这些标签。查询编辑器 v2 依赖以下标签。
RedshiftDbUser– 此标签定义查询编辑器 v2 使用的数据库用户。此标签为必填项。RedshiftDbGroups– 此标签定义当连接到查询编辑器 v2 时加入的数据库组。此标签是可选的,其值必须是以冒号分隔的列表,例如group1:group2:group3。空值将被忽略,也就是说,group1::::group2被解释为group1:group2。
这些标签将转发到
redshift:GetClusterCredentialsAPI 以获取集群的凭证。有关更多信息,请参阅设置主体标签以作为联合用户连接到查询编辑器 v2。 - 数据库用户名和密码
-
使用这种方法,还需要为要连接的数据库提供 User name(用户名)和 Password(密码)。查询编辑器 v2 代表您创建秘钥并存储在 Amazon Secrets Manager 中。此密钥包含用于连接到数据库的凭证。
- 临时凭证
-
使用此方法,查询编辑器 v2 会为数据库提供 User name(用户名),并生成用于连接到数据库的临时密码。
当您选择具有查询编辑器 v2 的集群或工作组时,根据上下文,您可以使用上下文(右键单击)菜单创建、编辑和删除连接。
浏览 Amazon Redshift 数据库
在数据库中,您可以在树视图面板中管理架构、表、视图、函数和存储过程。在视图中的每个对象都在上下文(右键单击)菜单中都有与之关联的操作。
选择表后,您可以执行以下操作:
如要在编辑器中开启查询表中所有列的 SELECT 语句启动查询,请使用 Select table(选择表)。
要查看属性或表格,请使用 Show table definition(显示表定义)。使用此选项可查看列名、列类型、编码、分配键、排序键以及列是否可以包含空值。有关语法的更多信息,请参阅《Amazon Redshift 数据库开发人员指南》https://docs.amazonaws.cn/redshift/latest/dg/r_CREATE_TABLE_NEW.html中的 CREATE TABLE。
要删除表,请使用 Delete(删除)。您可以使用 Truncate table(截断表)从表中删除所有行。或使用 Drop table(删除表)从数据库中删除表。更多信息,请参阅《Amazon Redshift 数据库开发人员指南》中的 TRUNCATE 和 DROP TABLE。
选择架构以 Refresh(刷新)或 Drop schema(删除架构)。
选择视图以 Show view definition(显示视图定义)或 Drop view(删除视图)。
选择函数以 Show function definition(显示函数定义)或 Drop function(删除函数)。
选择存储过程以 Show procedure definition(显示过程定义)或 Drop procedure(删除过程)。
层次结构树状图面板类似于以下内容。打开图标的上下文(右键单击)菜单,以查看您可以执行哪些操作。
创建数据库对象
您可以创建数据库对象,包括数据库、架构、表和用户定义的函数(UDF)。您必须连接到集群或工作组以及数据库才能创建数据库对象。
创建数据库
有关数据库的信息,请参阅《Amazon Redshift 数据库开发人员指南》中的 CREATE DATABASE。
选择
 Create(创建),然后选择 Database(数据库)。
Create(创建),然后选择 Database(数据库)。输入 Database name(数据库名称)。
(可选)选择 Users and groups(用户和组),然后选择 Database user(数据库用户)。
选择 Create database(创建数据库)。
新数据库将在树状视图面板中显示。
创建架构
有关架构的信息,请参阅《Amazon Redshift 数据库开发人员指南》中的 Schemas。
选择
Create(创建),然后选择 Schema(架构)。输入 Schema name(架构名称)。
选择 Local(本地)或 External(外部)作为 Schema type(架构类型)。
有关本地架构的更多信息,请参阅《Amazon Redshift 数据库开发人员指南》中的 CREATE SCHEMA。有关外部架构的更多信息,请参阅《Amazon Redshift 数据库开发人员指南》中的 CREATE EXTERNAL SCHEMA。
如果选择 External(外部),则可以选择以下外部架构。
Glue Data Catalog(Glue 数据目录)– 在 Amazon Redshift 中创建引用 Amazon Glue 中的表的外部架构。除了选择 Amazon Glue 数据库,还可选择与集群关联的 IAM 角色以及与数据目录关联的 IAM 角色。
PostgreSQL – 在 Amazon Redshift 中创建外部架构,此架构引用 Amazon RDS for PostgreSQL 或 Amazon Aurora PostgreSQL 兼容版本的数据库。还提供数据库的连接信息。有关联合查询的更多信息,请参阅《Amazon Redshift 数据库开发人员指南》中的通过联合查询来查询数据。
MySQL – 在 Amazon Redshift 中创建外部架构,该架构引用 Amazon RDS for MySQL 和/或 Amazon Aurora MySQL 兼容版本的数据库。还提供数据库的连接信息。有关联合查询的更多信息,请参阅《Amazon Redshift 数据库开发人员指南》中的通过联合查询来查询数据。
选择 Create schema(创建架构)。
新 Schema 将在树状视图面板中显示。
创建表
您可以根据您指定或定义表中每列的逗号分隔值(CSV)文件创建表。有关表的信息,请参阅《Amazon Redshift 数据库开发人员指南》中的 Designing tables 和 CREATE TABLE。
选择 Open query in editor(在编辑器中打开查询)在运行查询以创建表之前查看和编辑 CREATE TABLE 语句。
选择
Create(创建),然后选择 Table(表)。选择架构。
输入表名称。
选择
Add field(添加字段)以添加列。使用 CSV 文件作为表定义模板:
选择 Load from CSV(从 CSV 加载)。
浏览到文件位置。
如果您使用 CSV 文件,请确保该文件的第一行包含列标题。
选择文件,然后选择 Open(打开)。确认列名和数据类型符合您的要求。
对于每一列,选择该列并选择所需的选项:
为 Encoding(编码)选择一个值。
选择 Default value(原定设置值)。
如果您想增加列值,启用 Automatically increment(自动增量)。然后为 Auto increment seed(自动增加种子)和 Auto increment step(自动增量步骤)指定值。
如果该列应始终包含值,启用 Not NULL(非 NULL)。
输入列的 Size(大小)值。
如您希望该列成为主密钥,启用 Primary key(主密钥)。
如您希望该列成为唯一密钥,启用 Unique key(唯一密钥)。
(可选)选择 Table details(表详细信息)然后选择以下任何选项:
分配密钥列和样式。
对密钥列进行排序和排序类型。
启用 Backup(备份)将表包含在快照中。
启用 Temporary table(临时表)将表创建为临时表。
选择 Open query in editor(在编辑器中打开查询)继续指定用于定义表的选项,或选择 Create table(创建表)来创建表。
创建函数
选择
Create(创建),然后选择 Function(函数)。对于 Type(类型),选择 SQL 或 Python。
为 Schema(架构)选择一个值。
为函数 Name(名称)输入一个值。
为函数 Volatility(波动性)输入一个值。
按输入参数的顺序排列的数据类型选择 Parameters(参数)。
为 Returns(返回值)选择一种数据类型。
输入函数的 SQL program(SQL 计划)代码。
选择 Create (创建) 。
有关用户定义的函数(UDF)的更多信息,请参阅《Amazon Redshift 数据库开发人员指南》中的创建用户定义的函数。
加载示例数据
查询编辑器 v2 附带可加载到示例数据库和相应架构中的示例数据和查询。
要加载示例数据,请选择与要加载的示例数据相关联的  图标。然后,查询编辑器 v2 将数据加载到数据库
图标。然后,查询编辑器 v2 将数据加载到数据库 sample_data_dev 的架构中,并在您的 Queries(查询)文件夹中创建一个存放所保存查询的文件夹。
提供了以下示例数据集。
- tickit
-
Amazon Redshift 文档中的大多数示例使用称为
tickit的示例数据。此数据包含七个表:两个事实表和五个维度。当您加载这些数据时,将使用示例数据更新架构tickit。有关tickit数据的更多信息,请参阅《Amazon Redshift 数据库开发人员指南》中的示例数据库。 - tpch
-
此数据用于决策支持基准。当您加载这些数据时,将使用示例数据更新架构
tpch。有关tpch数据类型的更多信息,请参阅 TPC-H。 - tpcds
-
此数据用于决策支持基准。当您加载这些数据时,将使用示例数据更新架构
tpcds。有关tpcds数据的更多信息,请参阅 TPC-DS。
从 Simple Storage Service(Amazon S3)加载数据
将数据从 Simple Storage Service(Amazon S3)加载到现有表中。
将数据加载到现有表中
查询编辑器 v2 使用 COPY 命令从 Simple Storage Service(Amazon S3)加载数据。在查询编辑器 v2 加载数据向导中生成和使用的 COPY 命令支持从 Amazon S3 复制的 COPY 命令语法可用的所有参数。有关 COPY 命令及其用于从 Simple Storage Service(Amazon S3)加载数据选项的信息,请参阅《Amazon Redshift 数据库开发人员指南》中的 Amazon Simple Storage Service 中的 COPY 命令。
确认表已在要加载数据的数据库中创建。查询编辑器 v2 只能将数据加载到现有表中。
选择
Load data(加载数据)在 S3 URI中,选择 Browse S3(浏览 S3)以查找包含要加载数据的 Simple Storage Service(Amazon S3)桶。
如果指定的 Amazon S3 桶与目标表不在同一个 Amazon Web Services 区域 中,则选择数据所在的 Amazon Web Services 区域 的 S3 file location(S3 文件位置)。
如果 Simple Storage Service(Amazon S3)文件实际上包含多个 Simple Storage Service(Amazon S3)桶 URI 清单,选择This file is a manifest file(此文件是清单文件)。
选择具有从 Simple Storage Service(Amazon S3)加载数据所需的权限的 IAM role(IAM 角色)。
为要上载的文件选择 File format(文件格式)。支持的数据格式有 CSV、JSON、DELIMITER、FIXEDWIDH、SHAPEFILE、AVRO、PARQUET 和 ORC。根据指定的文件格式,您可以选择相应的 File options(文件选项)。如果数据已加密,您还可以选择 Data is encrypted(数据已加密),并输入用于加密数据的 KMS 密钥 Amazon Resource Name(ARN)。
对于 PLATION 和 ORC,没有任何文件选项可以配置。
选择压缩方法来压缩文件。原定设置为无压缩。
(可选)Advanced settings(高级设置)支持各种 Data conversion parameters(数据转换参数)和 Load operations(加载操作)。根据文件的需要输入此信息。
有关数据转换和数据加载参数的更多信息,请参阅《Amazon Redshift 数据库开发人员指南》中的数据转换参数和数据加载操作。
确认或选择 Target table(目标表)的位置,包括加载数据的数据库、架构和表名称。
选择 Load data(加载数据)开启数据加载。
加载完成后,查询编辑器将显示用于加载数据的生成 COPY 命令。将显示 COPY 的 Result(结果)。如果成功,您现在可以使用 SQL 从加载的表中选择数据。当出现错误时,请查询系统视图 STL_LOAD_ERRORS 以获取更多详细信息。有关 COPY 命令错误的信息,请参阅《Amazon Redshift 数据库开发人员指南》中的 STL_LOAD_ERRORS。
更改账户设置
拥有正确 IAM 权限的用户可以查看和更改同一 Amazon Web Services 账户中其他用户的 Account settings(账户设置)。该管理员可以查看或设置以下内容:
账户中每个用户的最大并发数据库连接数。这包括用于 Isolated sessions(隔离会话)的连接。更改此值时,更改可能需要 10 分钟才能生效。
允许账户中的用户将整个结果集从 SQL 命令导出到文件中。
加载和显示示例数据库以及一些关联的已保存查询。
查看用于加密查询编辑器 v2 资源的 KMS 密钥 ARN。
使用 SQL 笔记本(预览版)。
| 以下是针对预览版查询编辑器 v2 笔记本的预发行文档。文档和功能都可能会更改。我们建议您仅在测试环境中使用此功能,不要在生产环境中使用。有关预览条款和条件,请参阅 Amazon 服务条款 |
您可以使用 SQL 笔记本在单个文档中组织、注释及共享多个 SQL 查询。您可以将多个 SQL 查询和 Markdown 单元格添加到 SQL 笔记本中。SQL 笔记本提供了一种方法:通过使用多个查询和 Markdown 单元格,将与数据分析相关的查询和解释分组到单个文档中。您可以使用 Markdown 语法添加文本并设置外观格式,以便为数据分析任务提供上下文和其它信息。您可以与团队成员共享您的 SQL 笔记本。
如要使用 SQL notebook 功能,您必须向已具有一个查询编辑器 v2 托管式策略的主体(IAM 用户或 IAM 角色)添加 SQL 笔记本(预览版)功能的策略。有关更多信息,请参阅访问查询编辑器 v2。
要了解笔记本的演示,请观看以下视频。
创建 SQL 笔记本
选择
然后选择 Notebook(笔记本)。原定设置情况下,新的 SQL 笔记本中会出现一个 SQL 查询单元格。
(可选)选择 Rename(重命名)然后输入 SQL 笔记本的名称。
在 SQL 查询单元格中,执行以下任一操作:
输入查询。
粘贴您复制的查询。
(可选)选择 Add markdown(添加标记)添加 Markdown 单元格,在其中可以使用标准 Markdown 语法提供描述性或解释性文本。
(可选)选择 Add SQL(添加 SQL)及 Add markdown(添加标记)以插入额外的 SQL 和 Markdown 文本单元格。
打开笔记本
在导航器菜单中,选择 Notebooks(笔记本)。
选择要打开的 SQL 笔记本并双击。
与团队共享 SQL 笔记本
选择 Share toteam-name(共享到团队名称)。