编写联合查询
配置一个或多个数据连接器并将其部署到您的账户之后,您可以在 Athena 查询中进行使用。
查询单个数据源
本部分的示例假定您已配置 Athena CloudWatch 连接器并将其部署到您的账户。使用其他连接器时,使用相同的方法进行查询。
创建使用 CloudWatch 连接器的 Athena 查询
从 https://console.aws.amazon.com/athena/
打开 Athena 控制台。 -
在 Athena 查询编辑器中,创建在
FROM子句中使用以下语法的 SQL 查询。MyCloudwatchCatalog.database_name.table_name
示例
以下示例使用 Athena CloudWatch 连接器连接到 /var/ecommerce-engine/order-processor CloudWatch Logs 日志组中的 all_log_streams 视图。all_log_streams 视图是日志组中所有日志流的视图。示例查询将返回的行数限制为 100。
例
SELECT * FROM "MyCloudwatchCatalog"."/var/ecommerce-engine/order-processor".all_log_streams limit 100;
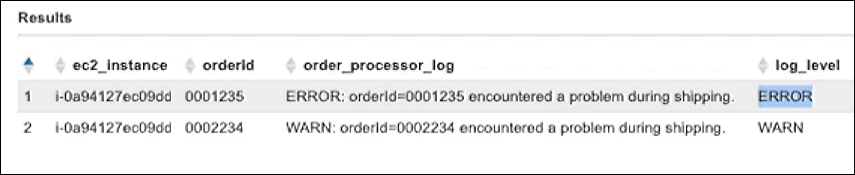
以下示例解析与上一示例相同的视图中的信息。该示例提取顺序 ID 和日志级别,并筛选出所有 INFO 级别的消息。
例
SELECT log_stream as ec2_instance, Regexp_extract(message '.*orderId=(\d+) .*', 1) AS orderId, message AS order_processor_log, Regexp_extract(message, '(.*):.*', 1) AS log_level FROM "MyCloudwatchCatalog"."/var/ecommerce-engine/order-processor".all_log_streams WHERE Regexp_extract(message, '(.*):.*', 1) != 'INFO'
下图显示了示例结果。
此示例显示了一个查询,其中数据源已注册为 Athena 中的目录。您还可以使用格式 lambda: 引用数据源连接器 Lambda 函数MyLambdaFunctionName.
查询多个数据源
我们来看一个更复杂的例子,假设一家电子商务公司拥有如下图所示的应用程序基础设施。
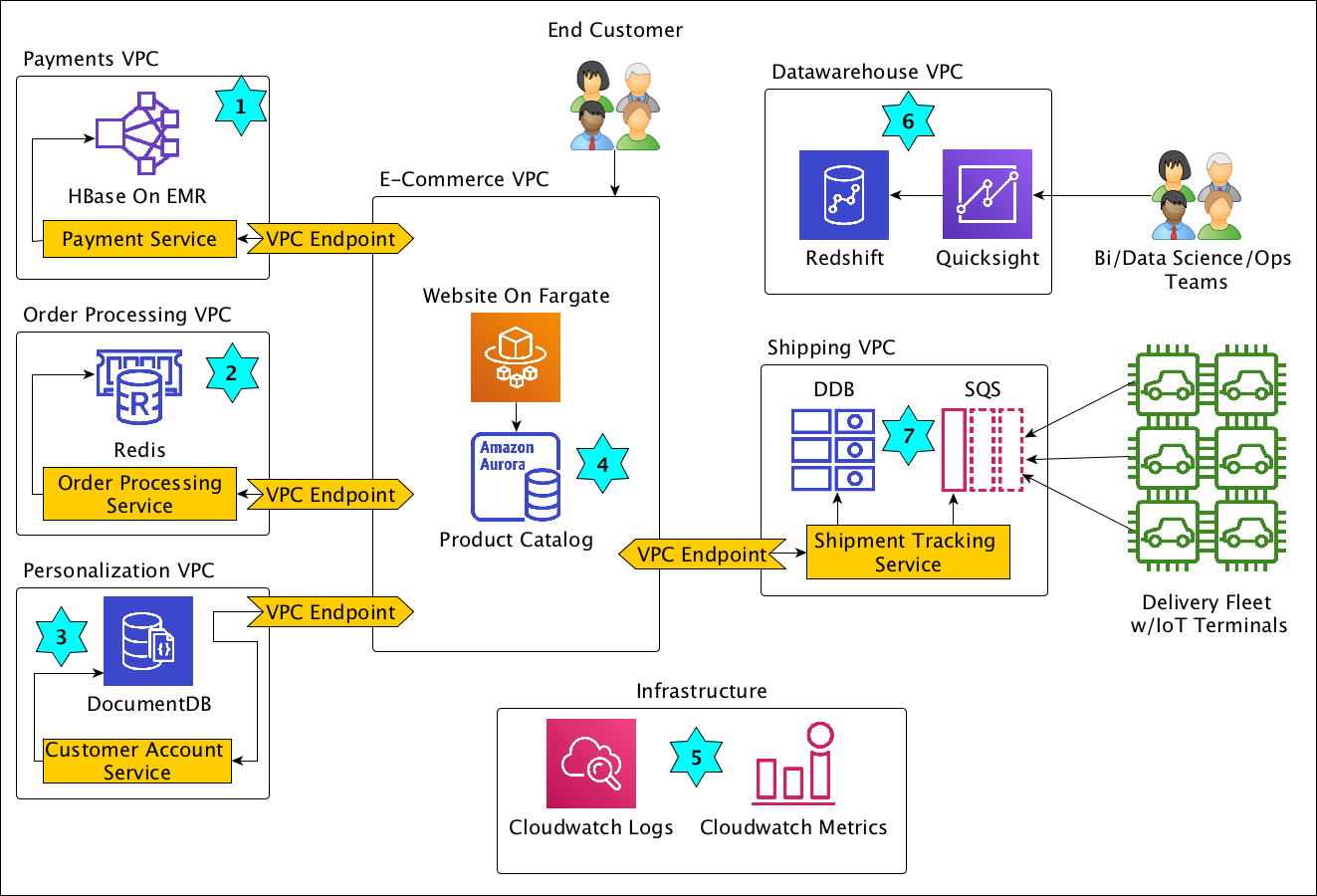
以下描述说明了逻辑示意图中的编号项目。
-
付款在安全 VPC 中处理,交易记录存储在 Amazon EMR 上的 HBase 中
-
Redis 用于存储有效订单,以便处理引擎能够快速访问它们
-
Amazon DocumentDB 用于存储客户账户数据,例如电子邮件地址和配送地址
-
Amazon Aurora 中的产品目录,供电子商务网站在 Fargate 上使用自动扩展
-
CloudWatch Logs 用来存放订单处理程序的日志事件
-
Amazon RDS 上的一次写入,多次读取数据仓库
-
DynamoDB 用于存储货件追踪数据
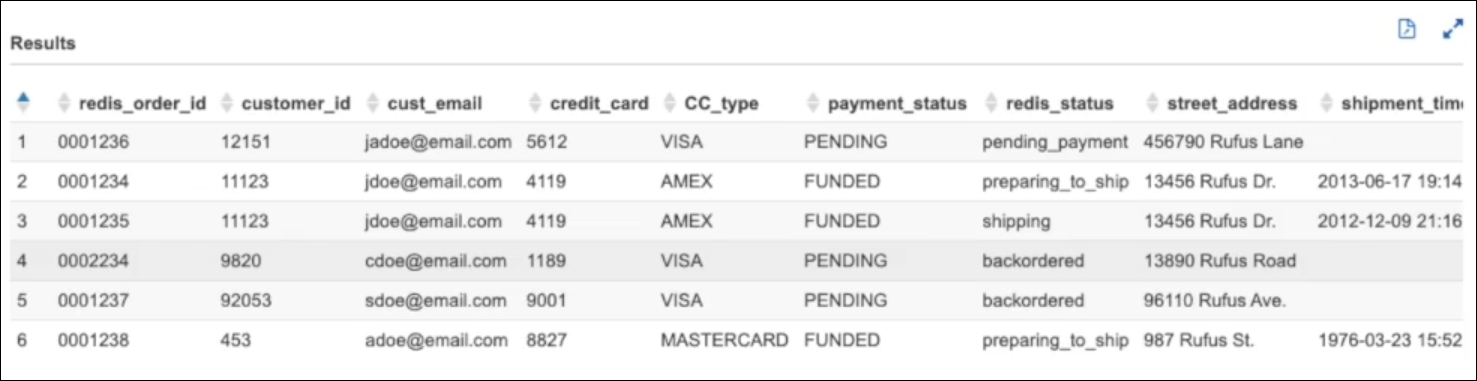
假设这个电子商务应用程序的数据分析师发现某些订单的状态报告错误。有些订单即使已送达,也显示为待处理,而其他订单虽然显示为已送达,但实际上尚未发货。
分析师想知道有多少订单被延误,以及受影响的订单在电子商务基础设施中有哪些共同点。分析师不是单独调查信息源,而是在单个查询中联合数据源并检索所需的信息。无需将数据提取到一个位置。
分析师的查询使用以下 Athena 数据连接器:
-
CloudWatch Logs
— 从订单处理服务检索日志,并使用正则表达式匹配和提取来筛选包含 WARN或ERROR事件的订单。 -
Redis
— 从 Redis 实例检索活动订单。 -
CMDB
— 检索运行订单处理服务并记录 WARN或ERROR消息的 Amazon EC2 实例的 ID 和状态。 -
DocumentDB
— 从受影响订单的 Amazon DocumentDB 检索客户电子邮件和地址。 -
DynamoDB
— 从发货表中检索发货状态和跟踪详细信息,以确定已报告状态和实际状态之间可能存在的差异。 -
HBase
— 从付款处理服务检索受影响订单的付款状态。
例
此示例显示了一个查询,其中数据源已注册为 Athena 中的目录。您还可以使用格式 lambda: 引用数据源连接器 Lambda 函数MyLambdaFunctionName.
--Sample query using multiple Athena data connectors. WITH logs AS (SELECT log_stream, message AS order_processor_log, Regexp_extract(message, '.*orderId=(\d+) .*', 1) AS orderId, Regexp_extract(message, '(.*):.*', 1) AS log_level FROM "MyCloudwatchCatalog"."/var/ecommerce-engine/order-processor".all_log_streams WHERE Regexp_extract(message, '(.*):.*', 1) != 'INFO'), active_orders AS (SELECT * FROM redis.redis_db.redis_customer_orders), order_processors AS (SELECT instanceid, publicipaddress, state.NAME FROM awscmdb.ec2.ec2_instances), customer AS (SELECT id, email FROM docdb.customers.customer_info), addresses AS (SELECT id, is_residential, address.street AS street FROM docdb.customers.customer_addresses), shipments AS ( SELECT order_id, shipment_id, from_unixtime(cast(shipped_date as double)) as shipment_time, carrier FROM lambda_ddb.default.order_shipments), payments AS ( SELECT "summary:order_id", "summary:status", "summary:cc_id", "details:network" FROM "hbase".hbase_payments.transactions) SELECT _key_ AS redis_order_id, customer_id, customer.email AS cust_email, "summary:cc_id" AS credit_card, "details:network" AS CC_type, "summary:status" AS payment_status, status AS redis_status, addresses.street AS street_address, shipments.shipment_time as shipment_time, shipments.carrier as shipment_carrier, publicipaddress AS ec2_order_processor, NAME AS ec2_state, log_level, order_processor_log FROM active_orders LEFT JOIN logs ON logs.orderid = active_orders._key_ LEFT JOIN order_processors ON logs.log_stream = order_processors.instanceid LEFT JOIN customer ON customer.id = customer_id LEFT JOIN addresses ON addresses.id = address_id LEFT JOIN shipments ON shipments.order_id = active_orders._key_ LEFT JOIN payments ON payments."summary:order_id" = active_orders._key_
下图显示了查询的示例结果。